There’s Just No Good Way Out. The only thing that is surprising is how long these retailers and malls, which have been spiraling down for years, were able to hold on.
By Wolf Richter for WOLF STREET.
The WOLF STREET market-cap-weighted stock index of 11 mall REITs made a heroic effort to bounce off the crisis low, and was able to double in three months, but has by now given up much of it and appears to be heading back to crisis lows. The index includes: Simon Property Group, Tanger Factory Outlet Centers, Taubman Centers, Cedar Realty Trust, Macerich, Seritage Growth Properties, Kimco Realty, RPT Realty, Washington Prime Group, Brixmore Property Group, and CBL, which is preparing to file for bankruptcy.
After Friday’s 2.2% drop, the index is down 74% from August 2016, when the Big Skid started. And from that heroic spike that topped out on June 8, it has now plunged 35% (market cap data via YCharts):
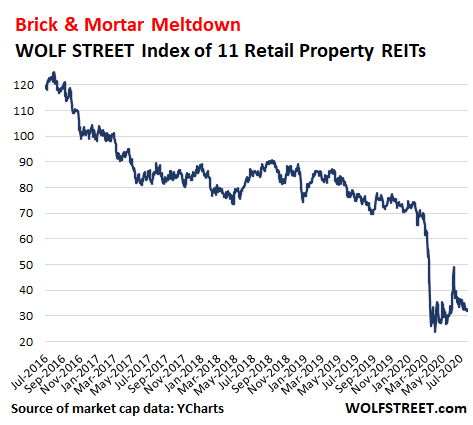
What will be left when the brick-and-mortar meltdown is over?
The process started years ago. Ecommerce, a structural shift in how Americans shop, has wiped out retailer after retailer, from big ones such as Sears Holdings and Toys ‘R’ Us, to smaller ones. It created a night-mare scenario for malls and landlords – including REITs – that own the malls, and for investors that hold the mortgages and the Commercial Mortgage-Backed Securities (CMBS) that these mortgages have been packaged into.
And now that the pandemic is compressing future years of brick-and-mortar meltdown into a few months, the whole schmear is coming apart.
Ascena, the latest in the Pandemic Series.
The latest mega-retailer that filed for bankruptcy and announced large-scale store closings was Ascena Group, which operated about 3,500 stores last year, but after closing all its 661 Dressbarn stores in December, it’s now down to 2,800 stores.
Its seven surviving brands are Ann Taylor, LOFT, Lou & Grey, Lane Bryant, Cacique, Catherines, and Justice. As part of its bankruptcy restructuring, it will close about 1,600 stores, beginning initially with 1,100 stores, including all its 264 Catherines stores, most Justice stores, plus some Ann Taylor, Loft, Lane Bryant, and Lou & Grey stores.
Ascena Group has hired a liquidator, SB360 Capital Partners, and the going-out-of-business sales are commencing at these stores.
In other words, Ascena had 3,500 stores a year ago, and plans to emerge from bankruptcy with 1,200 stores. The mall landlords end up holding the bag.
Bankruptcy fears have dogged Ascena for over a year. In June last year, as it was getting hammered by the regular run-of-the-mill brick-and-mortar meltdown in effect at the time, and with cash running low, it announced that it would close all its Dressbarn stores. In August last year, it emerged that its lenders, fearing a bankruptcy filing, began to prepare for it. Those fears were exacerbated last fall when Ascena tried to raise funds by selling two of its moribund brands, Catherines and Lane Bryant, but failed to find takers. The Pandemic just finalized the bankruptcy.
In May, when the company began reopening its stores after the lockdown, it became clear that it was over. Traffic to those stores was way down from the already miserably low levels last year, the company said in its update, and cash flow has been “significantly reduced.”
This is a pre-packaged bankruptcy filing where lenders have agreed to swap about $1 billion in debt for shares in the restructured company to emerge from bankruptcy.
In terms of liabilities, Ascena listed $3 billion, which makes it the third-largest bankruptcy in the Pandemic Series, behind J.C. Penney ($8 billion) and Neiman Marcus ($5.5 billion).
Among the biggest names that have also filed for bankruptcy during the Pandemic Series are: J.Crew, Stage Stores, GNC, RTW Retailwinds (New York & Co.), Brooks Brothers, Sur La Table, and Pier 1 Imports.
Jostling for position to be next in line is Tailored Brands, a holding company for Men’s Wearhouse, JoS. A. Bank, and other brands. On June 10, it confirmed in an SEC disclosure that it may have to file for bankruptcy.
Each one of these bankruptcy filings entails massive numbers of store closings, or the liquidation of the entire company or brand.
But ecommerce is booming.
Americans are spending their unemployment and stimulus money, and they’re buying lots of stuff, they’re just not buying it at the store. The ecommerce announcements by various retailers – those that have vibrant ecommerce businesses – have been stunning.
For example, Best Buy said in an update a few days ago that quarter-to-date through July 18, online sales have surged 255% (not a typo) compared to the same period last year. The Commerce Department will release second quarter ecommerce data in early August, and it will be stunning. But the business at malls is dead.
Mall mortgages collapse.
With thousands of stores being shuttered permanently, and with other stores that haven’t been shuttered yet unwilling or unable to pay rent, malls have been pushed to the brink.
Mall of America, the largest mall in the US, is now over 90 days past due on a $1.4 billion loan that has been packaged into a single CMBS (SASB CSMC 2014-USA). This is the largest mall-mortgage to be 90 days past due, according to Trepp, which tracks securitized mortgages for institutional clients.
Among the other large mall mortgages that are now 90 days past due is the $218 million loan backed by the 1.28-million-square-foot Crossgates Mall in Westmere, a suburb of Albany, NY. This loan has been cut into slices and spread over three CMBS.
Other mall mortgages that are 90 days past due include the $139 million loan backed by the 691,325-square-foot Poughkeepsie Galleria, in Poughkeepsie, NY, which is split across two CMBS.
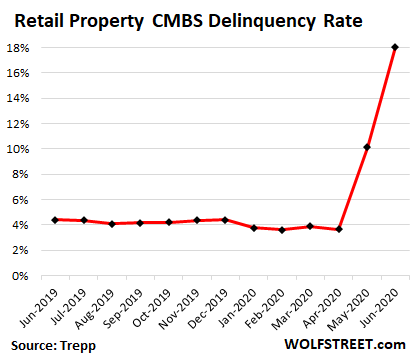
The delinquency rate for retail property CMBS spiked to 18.07% in June, according to Trepp:
CBL Property Group, a mall REIT with over 100 malls in 26 states and over $3 billion in debt, already issued a “going concern” warning on June 5 after it failed to make an interest payment on June 1. It then entered into a forbearance agreement with its creditors, and into discussions to restructure this debt.
July 17, Bloomberg reported that CBL was preparing to file for bankruptcy, and that it was in negotiations with its lenders over a restructuring agreement with which to enter the Chapter 11 filing.
On July 22, when the forbearance agreement expired, and there was still no agreement, CBL disclosed that it was able to extend the forbearance period and that negotiations continued.
Mall creditors are not amused. Mall properties have taken a huge hit in value – down 33% over the past 12 months and down nearly 50% over the past three years, according to the Green Street Property Price Index.
And no lender wants to end up with a bunch of zombie malls on their books. So they’re motivated to talk. But there is just no good way out.
Enjoy reading WOLF STREET and want to support it? You can donate. I appreciate it immensely. Click on the mug to find out how:

![]()
So we talking about financial crisis 2 the sequel or what?
Was looking back at data on Japanese bubble in 1989. Stock market cap to gdp was lower in Japan than current US values. Stock market fell 82%. Sure it is tough to compare different nations, but our asset bubble is very big. There is always a pin to pop the bubble and maybe the virus is it.
Interesting. I think Japan “helps” Japanese business differently, though? For example with tariffs that aren’t called tariffs, and subsidies? In contrast the Fed pukes free money into banks and finance and gambling…err…investment community. Japan’s seems more to the point and more efficient…at least compared to the US.
Timbers
re: “… Japan’s seems more…efficient…compared to the US…”
I respectfully disagree; 60-year comparison of US & Japan GDP (1980 = start of Japan miracle; 1990 = peak Japan; 2018 = most current data)
1980 Japan 951B; US 2,790B = Japan 34% of US GDP
1990 Japan 2,481B; US 5 ,747B = Japan 46% of US GDP
2018 Japan 5,489B; US 20,658B = Japan 26% of US GDP
I realize there’s more to GDP than US & Japanese government “help”, but the numbers tell quite a tale.
timbers,
In Japan, the government and people perpetually keep the same companies afloat. This has worked well for some industries like cars, but, some industries like electronics have seen market share crater. This has also been a part of creating social problems like one of the lowest birthrates in the World. Few new important companies are created any more and if enough of the current ones go it could crater the economy.
This is just another scam by the real estate industry.
They were slapping debt on these properties 10 years ago knowing that they would be defaulting.
No different than a private equity scams.
In the mob world it’s a bust out.
The new scam will be buying them for pennies on the dollar with kick back to the lender .
Savings and Loan scam 101
Found a research report on elevated stock prices in Japan vs US right before the bust. There was no textbook economic theory that could explain the total difference. If you plugged prices into economic calculations for stock prices you basically get that people were pricing in exceptional growth rates for too long of a period. The exceptional growth didn’t happen. There are always competitive pressures that will eventually do away with the exceptional growth. This in my opinion is where we are with the big techs. As a group they are priced at more than five times sales. They will all be at no more than two times sales at some point in the future and probably at some time in the distant future one time sales.
At least.
The first financial crisis was more to much debt. This one is more business is not profitable anymore. Half those malls will be empty and closed in 5 years.
One of the local malls by me has made money by selling the land to build condos. I bet they maintain an investment in the buildings at the very least.
Look for more of that.
Will there be a market for new homes? Problem with Covid is that i don’t see how the future will develop. Before i saw how it would develop but not if it would take a year or a decade
The Fed & Treasury Dept. has your back. This is a ZOMBIE feast. ZOMBIES will rule.
The whole real estate market will be going down. The commercial real estate market will go down, because so many businesses are in trouble.
Remember that Chinese investors were buying up US real estate for years, probably mostly communist cadres. Probably, that was mainly residential. Nevertheless, that means that if we exclude the communist party members, they may be motivated to sell RE property that they cannot even visit, even if it is property that they bought for investment purposes.
Still, they have been coming here for years to give birth. Thus, I suspect that thousands of the communist party members’ children are US citizens, who cannot be excluded. Thus, it is hard to predict how that will work out.
It’s important to mention that as far as I’ve heard, the Chinese buyers only bought up housing in large cities (in all countries) and in many places, were a large part of the reason, housing became so unaffordable. It was already very unsustainable, so in America if they are forced to sell it may crash the market, but, it could bring prices down helping reduce the current exodus.
My wife has a couple of mid range houses in Columbus ohio, one of which she is remodeling slowly.
over the last 3-4 months we have repeated calls to buy it for CASH, 10-15 times a week. Unbelievable!
The only thing I conclude there is a LOT & LOTS of money from around the world to get laundered through RE deals. Money laundering is demanding profession all over the world.
Cadres? You mean party member. Problem is the Chinese with money is just as likely to be connected to a communist party member as an American with money is to one of the to system parties. So in reality it is a ban on Chinese with money.
@Thomas Roberts: That is certainly true in the Seattle area. Asian buyers wanted properties in Seattle proper, or maybe Bellevue. They would not buy anywhere else, not even Redmond.
The Russians were a little smarter, and bought into the inner suburbs. (To be fair, most of the Russians actually live in the houses, and most of then speak good English.)
If the CCP folks have to do a fire sale, it would create a minor panic around here. I do not think it will happen. Flight capital from Hong Kong will probably pick up the slack.
Step back and look at the Global level of Coordination – Read the World Economic Reform Documents, United Nations Various Documents on Reputable Websites around the world… It is really hard to believe this is not totally set up and coordinated.. Look at the Central Bank and Government policies.. for the last 30 ++ years
Can you say “Global Reset”?
Very reassuring to know that the economy is in the hands of people who believe that shoveling coal into a burning house is some kind of fire science. Let’s hope they can run the food chain just as well.
From what I am gathering both parties know the hole is going to get too deep if we have to shut everything down again. Right now it seems everyone feels running $4 trillion deficit this year is doable. $7 trillion is too much from what I gather.
Future returns on nearly all financial assets are close to zero in real terms unless you leverage to a risky level. Going to really hurt if things get out of control and future real returns are negative.
Negative returns, negative interest rates. Problem solved.
/snark
Food chain? When you take a look at how much mid-west farmland and entire west coast real estate was “sold out” to “One Silk Road”, you will have your answer.
I haven’t seen any steak in local store for a month plus. But we have the I cant Beleive Its not Butter type of beef.
The profit margin on fake is higher.
New York strip fake.
A few random thoughts.
I still travel for work. Hotels are starting to getting pretty full and some of the nicer ones are charging close to full prices again.
Good restaurants with outdoor dining have long waits…even on Tuesdays.
Fannie Mae and Freddie Mac mortgage bonds sold to private investors – how safe? Forbearance will end in September. These are quasi backed by the taxpayers but were supposed to go private.
https://www.statista.com/statistics/206546/us-hotels-occupancy-rate-by-month/
Still quite a bit below the past. I suspect what you’re seeing is regional and brand specific. That is, people are flocking back to the big chains they trust to clean and distance correctly, and the others are taking a beating.
Lots of hotels are still closed, and some have permanently closed. In California, quite a few of them have been converted into homeless shelters during the Pandemic, and they’re no longer hotels. So the occupancy rate of the hotels that are now open is higher than it would be if all hotels were still open.
Yup, I’ve seen that same phenomenon here in South Florida back when indoor dining was allowed for a period of time. A lot of restaurants were closed (either completely or for in-person dining) so the ones that were open looked packed. But it’s an illusion, as the total number of people eating at restaurants was still way down.
You also see that with planes. I’ve had people tell me “The airlines seem to be doing okay; I was on a flight that was nearly full.” But of course, the TSA data (which the airlines can’t manipulate to jawbone their stock prices) shows ridership at between 20-26% of last year’s. Which means that the airlines are flying a lot fewer flights (obviously) so the ones they are flying are much fuller.
As an Airline Pilot I have been on the road continuously throughout this ordeal. I fly on average three days per week and spend two nights per week in hotels throughout the U.S. domestic system. I can say without hesitation that the Hotels we stay in which range from 3-4 star are predominantly empty. My estimate would be no more than 25-30% occupancy! My unscientific method of tracking is “do not disturb” door hangers and lobby traffic. I also take the time to talk with hotel staff and wait staff in the locations we stay. All are having difficulty!
As for the Airlines……we have consolidated operations into fewer flights and terminal space thusly creating the appearance of crowds. However, we are operating at around 25% capacity in a now declining market.
Government support will expire the end of Sep. and we are expecting a large wave of involuntary furloughs to happen despite voluntary early out programs which will have already reduced head count by 25%.
Times are not good and the recovery has been nascent at best. This will take many years to resolve for the airlines and the other side may very well be a smaller industry! Many businesses are learning that they can survive on less travel.
Wolf, thanks for the blog!
Good points on hotels and restaurants.
The ones that survive will have much less competition.
And I should have added i am mostly staying in the suburbs/mid tier cities and not in major city downtowns.
Great data points from 2banana and all responders. Thank you. Here are some restaurant observations for the Wilmington DE area.
Multiple fast food drive through locations are a continuous string of cars at 2:00 and 3:00 in the afternoon. If they can get a break on rent and other fixed costs, they might be able to break even.
Several chains like Olive Garden, Outback and Firebirds have opened dining rooms, but are ghost towns (I have eaten in all three). Two of those three are in a dining area hot spot near a large hospital complex. They were formerly packed at 2:00 & 3:00 in the afternoon. They have to be hurting big time.
A local restaurant called Cross Roads just announced shutting down. It was a low priced and lots of food type place. They claimed 1,000 customers a day before the virus – judging from their parking lot I believe it. It had to be a razor thin margin operation. No way they could make it with the government restrictions on seating.
Going forward I anticipate a steady drip drip drip of bad economic news.
No inflation?……Gold crosses 1900.00 per ounce. This market is the only one which is not being manipulated upward…..its being restrained by the banks. A true signal for what is occurring.
We are losing control of our markets……correction…… the fed and incompetent leaders are losing control of the markets.
In 1960……ask not what your country can do for you….ask what you can do for your country
Today…….ask not what you can do for your country…..demand and steal whatever isn’t nailed down and squander it.
History will not be polite to our generation…..we were handed so much and fumbled it all away. Sad. Hopefully the kids can pick up the pieces.
Schiff’s podcast today talked about the price of an ounce of gold in U.S. in 1790s bring about $19.20, meaning the dollar has lost 99% of its value since then, most of it since the creation of The Fed.
And yet for some strange reason everyone prices gold in dollars.
And gasoline in tenths of a penny…but would any of us toss it out the door to kill weeds?
or their own sovereign currency
Apple
You’d rather have gold priced in Mexican (or Argentine) pesos, or Russian rubles, or (gasp!) Turkish lira?
Schiff a idiot. That isn’t how you acquire purchasing power. Gold isn’t money, it’s a store of value.
“Shiff a idiot”.
Don’t be too naive to the powers of govt. FDR era and Nixon era made this clear when they outlawed silver and gold at the stroke of a pen. The debasing of the dollar is quite common every few cycles it seems. I would consider this the new normal until our appointed leaders say otherwise. You can clearly see the gold bubbles when the human sentiment gets fearful. It’s too obvious. All the doomsdayers stock up on alcohol, guns, and precious metals. I don’t discourage in taking a position in precious metals, however. I just wanted to point out that the human behavior is spot on.
A relatively minor point, but silver was never affected by anything FDR did. It remained the primary metal in coinage in the US until it became so valuable in the 1970’s that coins were being melted down for the metal. So any any point, US citizens were free to buy all the silver that they wanted.
Currency isnt a store of value. There fixed it for you Bobby Dents.
“Schiff’s an idiot”. What does that make Bobby, Dense?
Robert Moran An idiot who has been right all along Troll much .?
How much would $19.20 be if you invested it in t-bills since 1790?
One dollar invested in US stocks in 1880 was worth $100,000 by 2008.
Gold and silver have been VERY poor long term investments compared with anything that compounds.
That would mean a 10 fold increase in stock value every 26 years. I somehow doubt that even with special years.
ps my guess 2008 was a top and 1880 was a bottom year aka special years.
Nick Kelly
Winner! Winner! Chicken dinner!
$1 dollar invested in 1880 (140 years ago) at 8.57% compound interest will indeed equal $100,000 (actually, $99,857) 1n 2020.
This calculation is entirely plausible (verified on excel spreadsheet).
I’m not a stock market expert, but as an investor, over the long haul, I expect the market to average 9-10%/year.
nick kelly
That is a common, poorly though-out, and useless comparison. Gold was valued at FIXED PRICES up until the Nixon Shock in 1971. So any comparison before that date is apples to meatloaf.
Since that time, gold has outperformed the DOW, even taking into account the latter’s absurd, current over-valuation.
nick kelly,
That’s true, but, not necessarily true going forward. Since then the economy has grown by many times, but, has mostly leveled off over the past couple decades. Stocks are currently valued at several times their realistic worth and housing/land is expensive, risky, and difficult to own and maintain. The economy will probably start growing again, eventually (it might grow alot), before leveling off for probably a long time.
In this meantime gold, silver, and platinum are among the best and safest investments, so long as you can store it properly and/or buy “good paper gold” (if it exists).
Tinky, do a little more research. The fixed gold price was only for government-to-government transactions, even then the US government limited those transactions. There was an active market for gold (Industrial and jewelry, and coins) that was priced differently than the official fixed rate.
Like Wolf’s, my wife is Japanese and she is as fearsome with the shopping costs as their reputation will have it. She tells me basic groceries (here in Aus) have risen by 20%. I’m not sure how it’s being hidden, maybe by jacking items not in the CPI basket of goods or by removing the number of Specials usually offered but inflation is real and significant. I’m sure if we lived only on bread and milk the figures would hardly have changed.
Milk, eggs, and bread are the big “loss leaders” items the stores lose money on to get you in the store. Their prices are often calculated very differently from other food items.
Shrinkflation is the term given when items don’t go up in price, but, you get less for the same price. This is mainly where the increased cost has been hidden.
CPI basket of goods = junk measurement. It’s partly screwed up by loss leaders and by substituting inferior items at the cheapest available prices with whatever came before.
I have been saying for the past 2 years that whoever is calculating the costs for groceries has been keeping it deliberately low…shopping for a family of 4 is extremely challenging even if you shop at the Walmart grocery store which in our area has the lowest prices..
Wolf,
Hmm…you could take a midsized mall of 500k sf, level it, set aside 20% for common areas, and build 800 1 bedroom (500 sf) apts…*per floor built*.
And the parking is 100% built in already…
Rents have been soaring for 5 to 7 years…the only question is why it takes dead malls so long to re-purpose.
Any RE personages out there care to chime in?
Sure you could, but a piece of land where you have to tear down buildings to redevelop it is worth a lot less than the loan that backed the mall.
So the landlord lets the mall default and walks away.
The lender gets the mall, sells it to a property developer at a huge loss. If the lender has a lot of these kinds of properties (such as a smaller bank), it might collapse.
Property developer who bought the land at low cost invests money and builds housing and may come out ahead.
This only works where housing is needed. A mall in a distant suburb may not be the right spot for housing.
In the final analysis who ends up holding the bag with all of these defaults and bankruptcies? We are just a giant Zombie economy? the Federal Reserve buys everything with Wall Street continuing to make all the money?
Mountain View converted a couple malls decades ago. Mayfield Mall was the first Indoor Mall in NorCal, closed in the 80’s, sold to HP, now Google property.
The Old Mill was a fun indoor mall with a creek, trees, water wheel, “Outdoor” Mexican restaurant, Fargo’s pizza parlor, Movie theater, converted to a large Condo development in the 80’s. The shops inside were not terribly interesting or busy as in the case of today’s malls. One can imagine Woz and Jobs entertaining back of napkin ideas in the place.
Both of these places walking distance to the CalTrain San Antonio Station which did not exist until 1999.
But Wolf is right, forget large Office and condo developments in Redding or Bakersfield.
Sort of a double-edged sword though. That repurposing only really works in areas with a housing shortage, as you alluded to with the reference to Bakersfield. However, if “work from home” becomes permanent, as I suspect it will, the housing shortage in many urban areas will fix itself, as a lot of people were only living in crowded, expensive urban areas because they had to, not because they wanted to.
re: ” One can imagine Woz and Jobs entertaining back of napkin ideas in the place.”
You can imagine it, but it didn’t happen (they did sometimes meet at The Oasis):
https://en.wikipedia.org/wiki/Homebrew_Computer_Club
Boomer
re: “…In the final analysis who ends up holding the bag with all of these defaults and bankruptcies?”
1) My first guess would be pension funds (AKA people managing other people’s money)
2) My second guess would be…no, wait a minute; #1 is the only answer.
Walmart for instance likes to build stores at the edge of one city and another. In my town for instance, WMT is part of a mile long complex, close to a freeway. However since they built that mall, the commuter train now connects. Roads have been improved. There is rural space surrounding. If you were looking for property for housing this is it. Excess parking, is instant building space. Switching commercial tenants seems to take an eternity. Property sits idle for decades sometimes. Housing moves much quicker. Downsize, and leave space for shops to serve residential customers. There is nothing to most of this construction, concrete tilt-ups. Knock em down and start over.
Wolf:
Why not retrofit the empty Malls into mixed-use retail where 55+ Seniors would spend their money, and use the upper levels for small 2-person condos?
Landlord MGMT companies are gouging renters to the point where the Feds should impose rent-control! This is something that Dr. Carson (HUD) should be on top of; when will the gov’t servants begin to care about the conditions of its Country and the little people?
Malls are not convertible to condo’s. to install the needed infrastructure, (mostly plumbing) it would be necessary to do so much demo, that it is cheaper to level it and build from scratch.
That is simply not true Jpup,
Having ”estimated” construction, including tons of remodels the last 50 years or so, I can say that with certainty, unless the overall situation has changed ”dramatically” since mid 2019, which I seriously doubt.
Saw cutting up to 6″ slab on grade is about $1 per LF, so $2 per lf of trench, complete removal of concrete another $1-2 at most. Digging and pipe installation by PB after that is same as new construction. Cutting of vertical concrete walls to provide windows or doors varies, as you would imagine, depending on elevation, etc. But not seen it over $5/LF.
Not sure where the idea of it being too expensive to retrofit older mall or any other buildings, but it has been done a ton for at least the last 3 or 4 decades that I have been bidding and working on in CA especially because of cost of all construction, as well as all over USA.
Think conversions of old Walmarts into Tractor Supply stores and many others… old grocery mkts, Kmarts, Sears, etc., etc.
Complete ”mass” demo of older buildings is usually because new owners want a new look, or going to build greatly increased height , many more stories where current foundations and other structural components are totally inadequate.
There is a lot of difference between converting a building from commercial to commercial and commercial to residential. You are comparing apples to oranges. I am yet to see a single mall converted to residential condo’s… there is a reason..
DoUrHomewk
Speaking as a “55+ senior”, who the hell wants to live in a “small condo” above a cheesey mall?
This just sounds like a not very good answer in search of a problem; Dr Carson has more important problems to solve than saving the butts of shopping mall landlords.
Especially if the distant suburb doesn’t have a mall close by.
Turn all the closed stores into government housing after purchasing for pennies on the dollar. Problem solved!
I would suspect cities would want their cut, and then there is all the rezoning involved, environmental assessments, neighborhood complaints about traffic, etc, a ton of barriers to overcome.
It isn’t easy, and then there is always the danger of community activism. Look at Cupertino for example. It tore down Vallco park, a mall that was dead about a decade ago, and is starting a set of “housing” project. That process took five years just to get sufficient approval for teardown, after numerous challenges. Finally, the plan can go ahead.
Of course, with the virus, we are talking another delay, and if valley economy takes a hit, the entire farce would collapse. Which probably is for the better considering it will keep traffic manageable.
Funny you should mention Vallco, as that was one of the places I was thinking about when I read the article. seems it died in the 90s and couldn’t figure itself out, despite the massive influx of people into Silicon Valley over the years. I could never understand how such valuable land could produce so little. And yet you cross the street and Main Street with it’s very mediocre restaurants was packed! The line for that entire wall of tesla chargers seemed endless in the evenings.
It’s the weirdest thing. I remember seeing the information sessions and petitions from Cupertino residents against Vallco at the library there, mostly older residents. Then as the issue drew close to a vote, I saw the developers hiring a bunch of what I would guess are non-residents with provocative signs designed to elicit sympathy: “like more housing for low income, more housing for teachers, etc.” Making it like the residents of Cupertino are a bunch of NIMBY and privileged instead of the developers trying to make their quick buck.
Yeah, Vallco was weird, I think what kept it alive for a while was the AMC, the bowling alley, the ice rink, the Alexander steakhouse (I am not sure if that was on the mall property).
Well, where there is money involved, eventually there is a way or these people go bankrupt.
Agree MCH,
In CA especially, the local and state guv mints are the biggest hurdles to any development: last house I built in CA, it was $22,000 in guv mint fee and six months for permit to REPLACE a house destroyed in EQ; one year later in FL, it was $3,000 and two weeks- and the time only because the plans had several errors caught by city– and that house was all new, and included cost of water and sewer connection…
Few years later in mid fly over area, it was over the counter at first walk in, $150 TOTAL guv mint fees, including water connection, but septic system was another $700 by contractor…
Septics across N America are nowand usually in excess of 20K as all jurisdictions require engineered mound systems, with pumps, filters, etc. . It has been a real nightmare.
Unless of course, Captain Midnight just happens to have one grandfathered in on some property, Lord knows how long ago and who installed it? Of course that doesn’t work if you have snoopy neighbours or someone bitter about their own installation. Privacy rules.
regards..Capt Midnight.
@Paulo – I’ve a well/septic system with a nearby wetland. Might not pass current perc tests. With village water and sewer costs ratcheting up a grandfathered well/septic is golden.
Floor plate issues–you need to have a max of about 30 feet from corridor to window to make a desirable unit.
Wolfie,
What are you thoughts on power centres and strip malls? Not all retail properties should be painted with the same brush.
“Wolf”
Haha! Wolf, if you ever need info about Telecom, I’ve been a site acquisition agent for 20 years in the USA. Vertical RE (cell towers) is my specialty. Keep up the good work, Sir!
Cell tower properties are probably the best properties to own that are part of the IYR R.E, ETF that is starting to turn downward.
The Space Force will need a lot of bases. The Prez will requisition these malls so as to better prepare us for the coming alien invasion.
… or something.
Someone better think of an innovative way to repurpose our commercial spaces.
They make great mini, boat, and rv storage areas.
…and local farm land.
If you finance to remove the asphalt payback is 100 years?
It could be turned into community farmland.
Giant porta pottys for homeless
Given our present state of the nation we may need to take all the empty mall space and turn it into homeless shelters and Covid medical wards.
Roller-disco pinball-parlor gaming-center crematoriums, with some space for package delivery systems?
Descena.
Bestbuy has stepped up its online service. I ordered a cable on Friday and they delivered it on Monday afternoon. It was $0.01 more expensive than Amazon, but I’m mad at Amazon right now.
Amazon is consistently higher prices than either WalMart.com or any of the specialty retailers. That “free shipping” is costing you a fortune.
After averaging over 400 Amazon orders per year for a decade, we are purposely moving our online ordering to Walmart and a handful of other online retailers. Amazon is getting too pricey and we can get better or equal service from the others.
Plus, Amazon is difficult, if not impossible, to get on a phone call with these days. We had a item not get delivered and we tried to speak with an Amazon rep, but could not find a customer service number that would connect to a human.
To get Amazon on the phone you have to look carefully in customer service and provide your number. Then they call you. I noticed in the last 4 weeks they hid it even deeper and changed the pages with the call request.
Anthony,
I just ordered in a new mattress from Costco. If it is too firm we will put it in the spare room we are remodeling and get the medium. $120 off, lots of varied reviews, and free delivery to our boondock.
Screw Amazon. The Mortar retailers of furniture in our nearby town are real bandits, actually. Real bandits. Costco products are usually quite good, imho, plus returns no problem.
Paulo, e have been buying more at Costco also. They opened a new store a mile from us a short while back. Love the place.
Glad to see people are waking up. Amazon made it too easy for us lazy Americans. I have added Target to my list to compare also; free shipping and 5% off with their card.
Tax benefit went away also for Amazon. That was a big draw originally.
A lot of people being unemployed due to closed shops and these people will have a hard time to find new emplyment paying a living wage.
My god, they expect a living wage? We’ll just have to keel haul them and get that washed out of their minds. Don’t they know about living on credit? Haven’t they heard of free advice on career change planning where 10K compete for one job? Are there no openings for free education at Harvard Law School or Wharton Finance? Then they can just roll on the dole!
Not having much work lately gave me the opportunity to do some sailing. Tacking into a headwind was the thrill of the day.
It’s easy, just “Find Something New ™”
It’s gonna be a huge shock to the 6-figure Gen-X-ers (making peak career money) when they get permanently paid-off (bc Corporate America no longer wants to pay their salary). They will soon learn what the Boomers already found out: your graduate education will get you the next job at Home Depot @ $11/hr, and Kroger $9/hr with zero benefits.
Just when you need a good Counselor, you can’t afford one!
Welcome to 21st Century America:
The Land of Milk and Honey!
The thing that makes investing fun is that a lot of the news is priced in. The outlet mall on the list is priced at roughly 1 times sales and Amazon is priced at 5 times sales.
These zones could be turned into military bases to be used in the inevitable war against whichever country gets the blame for all this mess.
That’s assuming the neo-cons get back into power in November
Which is 100% they will as both choices are neo cons. People who support peace are not allowed to run.
For example…. Current dude said he would end some of our forever wars. Remember how the bi partisan and government/business Establishment reacted to that? Supporting peace in this nation is The One True Unholy of Unholies no one can cross.
Yeah the tricky bit is picking one that is plausible and doesn’t have nukes, or friends with nukes. Actually scratch plausible I forgot the illegal war of aggression in 2003.
Wolf,
Do you think the banks are selling the stocks? Is that how they will make their money now? They are the market makers right?
“Daddy, what were malls?”
I copied the paragraph about Mall of America and texted it to my son who has lofty aspirations in the area of finance.
He responded by telling me that my message triggered an Apple Pay suggestion.
Freeking 1%, they’re way too deep into my virtual pocket.
Yet another fish-hook graph. Expecting many more of these. Beware of the barb…
Was looking back at data on Japanese bubble in 1989. Stock market cap to gdp was lower in Japan than current US values. Stock market fell 82%. Sure it is tough to compare different nations, but our asset bubble is very big. There is always a pin to pop the bubble and maybe the virus is it.
“Sure it is tough to compare different nations..”
I would think that the ‘science’ of economics would figure this out. So, you’re probably right — look out below!
Not to worry, Munchkin will BAIL them out, at least that’s how it seems to be going anymore. No realities to deal with anywhere, except for retirees with savings who have been cut off at the knees and forced into the markets they left once their brains began fading. Like mine.
Happy Days are here again, eh?
You ”nailed it” JV: thought I was finally really and truly ”retired” ,, with your brain part exactly correct, and only having to be concerned with maintaining my ”liquidity position (HAH),,, but not so fast for this old guy it appears, as my very well crafted financial plan going to heck in a handbasket with the various and sundry malarky(s) going on by the FRB and it’s owners etc.
Very helpful presentations by Mr. Richter, and also the many knowledgeable comments, are giving me at least some idea of where to go with investments going forward, though, so far, still thinking to go back to RE when the dust appears to have settled, which appears to be
2-3 years or so as usual in the past five or six decades/crashes…
Thanks to you all.
I like reading Hussman. He basically says the Fed creates a lot of zero interest money and buys up assets. The zero interest cash is hot money in society that is difficult to hold when everyone is getting rich with assets going up. But assets don’t go up forever and usually you are better sitting in cash for a few years until market corrects to something close to long term trend line.
I have kind of changed my mind and just say over the long term SP500 should be priced around 1x sales which is an easy number to look up and can’t be manipulated. That’s about 1400. Easy money has it pumped up close to 2.5 sales.
There is something to be said for the PS vs. the PE ratio…people don’t realize just how many shorter term manipulations GAAP allows…
But one shortcoming…PS really doesn’t incorporate/reflect impact of interest rates on DCF model of businesses-as-cash-in-cash-out machines.
If you Nail something, best you Trademark the thing, lest it turns into a religion.
Joe Rogan announced he’s moving to Texas. This is a guy sho supported Sanders for president and has more money than he will ever know what to do with. And even he can’t take L.A. any more. So it isn’t about the money.
We are seeing a seismic shift in both where and how people will live. Big cities are dead. Small cities/towns are the future. And with this change will come massive changes for retail. Giant malls and big corporate chains will go the way of cities. Small retail, mom and pop shops, independent restaurants, bars, etc are the future.
In a world of 24/7 tech, self driving cars, Twitter mobs and real life riots on the streets people want a simpler time, if only superficially. Where I live the most expensive per sq ft homes are pre-WW2 homes. They cost a ton to maintain and on paper you get a much better deal with new. But people will still punk down $750K for a 1500 sq ft home built in 1922 that needs $50K of work instead of $500K for a home twice the size that needs nothing. I see the same with cars are hot again. Well maintained luxury cars from the 90s and early 00s are in high demand, like a BMW E39. That era was right before cars stopped being cars and started being computers that you could drive. On paper a 2020 BMW 5 is heads and shoulders better than a 2000. But the 2000 is a much more fun car to drive.
And this fits in with wanting to eat at a local restaurant, shop at local stores, be part of a community. It’s the inevitable backlash to the digital age that will swing the pendulum the other way in all aspects of society and commerce.
Nostalgia is also a dangerous form of comparison. Think about how often we compare our lives to a memory that nostalgia has so completely edited that it never really existed.
-Brene Brown
I, for one, do not think that those buying older homes and cars are always “nostalgic”.
Our last home (and the newest one we ever owned) was built in 1992. When you took to do any work on the framing, and you looked at a cross section of the lumber, you could see narrow(er) rings. When you go to a lumber yard now, look at the wood at the end grain… the rings are much thicker because it’s fast growth wood which is significantly weaker and more prone to insects and warping. My daughter’s “ex” house in Clayton, CA was built with redwood. It was built in @ 1960. If you cut into the framing, you could toast a carbide blade – and it was naturally insect resistant. Roof systems were stick built vs. trusses and were sheathed with plywood vs OSB. Interior moldings were oak, Doug fir, poplar, clear pine – not cheap finger jointed junk or cardboard (which is what MDF is). Doors were solid wood vs. hollow core. Yes, they need work… but you start with a much better product .
Cars? Same thing. The current cars are not built to last. My newest car has a CANbus to control virtually every function in the car – from the heater controls, to the radio to the backup camera to the lord knows what else. The connectors on this car can fail after time. To repair them requires the entire disassembly of the interior. If you don’t repair them, the features of the car are useless. The nav screen goes dark. The radio gets a mind of it’s own. The center stack “screen” starts flashing and rebooting like an old MS computer. I will not own that car past it’s warranty expiration (which, for the first time in my life, I extended due to the CANbus issues). Our “old” car is a 2003 BMW. We love that car because it’s not a nanny car…. the steering wheel doesn’t “shake” because the cameras think it’s wandering (the lines are wavy on the road), it doesn’t brake for you (sometimes nearly causing an accident because it misinterprets data from it’s sensors)… it doesn’t “report” back to the manufacturer, nor does it rat you out to the insurance company / police in the event of an accident. With reasonable maintenance it runs fine. In fact there’s a site on Youtube that features a young man who buys older (E39, E38, E46, etc) BMW’s and restores them for that reason.
Several years ago, I read a book titled “Freedom” by Daniel Suarez. It is a science fiction book….. while some of the concepts appeared really “out there” at the time (this was back around 2010), it now appears somewhat prescient….. One factor was how the youth moved back to small towns and opened up cottage industries in secret and built their own economies. Interesting reading in these times.
Great author. I’ve read all his books. “The Kill Decision”
was another good one by him.
Friday night fish fry was packed in my little town bar last night. The corner store having a record year. Same as the local hardware & lumber company.
New home construction is booming.
It will be interesting to watch how this all plays out.
At this point, all the major cities near us, have failed miserably at protecting citizens & business. PC is more important.
Got a 2001 BMW v8 X5. Fun to drive on the highway.
Towns.
Places where everything is bought online and work is hard to find. Its future is none.
The US has a habit to not support its cities so i thing it will be slowly disappearing.
I’m probably the only commenter who actually likes shopping. Twenty years ago, I already thought there were too many chain stores. If I could see that multiple stores for every chain in small towns was a bad idea, why couldn’t the professionals see it. They should have seen it and stopped investing. But these guys are not deep thinkers and they went off the cliff, like they always do.
I really don’t feel bad for the losers in this game. But the malls and their investors are not the only losers. I’m a loser too. Many of the stores I love are gone. Now there are not many good ones left. Hopefully, the talented product creators will find their way back to Main Street.
Petunia,
You’re not the only one here who likes shopping, far from it, but there are not enough of you to keep these big malls alive. That’s the problem.
Wolf,
Since I posted this, I’ve been thinking about what would make a great mall. The biggest problem with the current ones is the lack of curation. They all look alike. These mall owners are landlords and all they care about are secure rent streams, which favors the big retailers over and over again. Until now.
I think the future of malls is probably a very curated co-op of retailers whose focus is retail and customers. The draw will be the mix of stores unique to the location.
Let’s not confuse the death of malls with the end of retail. It’s easy to convince people that mass produced items are unique and personal, if you make too many of them. Just about everything in this economy depends on over capacity. We are programmed to fear shortages. Marketing like TJs is a solution. You never know what they will have, you know it will be good. Retail needs to surprise the shopper, to keep them interested. If I was young I would go into retail, the second wave will be the golden age.
“Marketing like TJs is a solution. You never know what they will have, you know it will be good. Retail needs to surprise the shopper, to keep them interested. If I was young I would go into retail, the second wave will be the golden age.”
YES! I AGREE! i’m preparing for this, too. i SEE it.
I am not much of a real estate investor, but I wonder if it’s not the tax laws on depreciation. At low interest rates the the depreciation more than offsets the interest payments which are just rolled over so that the property is cash flow positive even though you have gaap losses. I wonder if this is what led to the over building of retail. Congress could speed up depreciation and save some malls and REITS but it wouldn’t be the right thing to do. Some probably will get saved by being able to refinance from 3.5% to something lower.
I think all the overbuilding came from too much passive investing on Wall Street. It’s not their money, so they put it anywhere that doesn’t sound too crazy to the investors. They take their fees, fund their buddies, and don’t worry about the consequences. Retirees are left holding the bag. Wall Street is the reason social security can never be privatized.
Petunia, “Wall Street is the reason social security can never be privatized.”
This is a very telling statement. I never thought about that as a consequence of privatizing SS. If that were to happen, guess how many seniors living on SS (and maybe a small pension) would be duped by financial slugs, con men, bankers, etc, and end up eating cat food for the remainder of their days.
I’d guess most of them.
I’m not so sanguine about SS as it is now. Granted they will crank up the printing press to even more unimaginable levels but what will we be able to buy with it?
well said. Wall Street is to blame for much wrong with USA. Wall Street is NOT free market. Recall they are CONSTANTLY getting bailed out over and over again
Old-School.
Depreciation is a paper deduction which reduces taxable income. Debt service is a real expense. If there is no taxable income, the interest still needs to be paid, unless other arrangements are made. You can drop the IR from 5% to 3.5%, but if income isnt even covering expenses, the negative cash flow after debt service will still increase. The probable repeal of Prop 13 in California in November on C&I will be interesting
Shopping is an American pass time.
Few retailers own all the brands.
Simon malls is bidding on clothing companies, keep staff, keep stores open all we need is our rent.
Tangers outlet malls are full of window shoppers, retail therapy shoppers and huge parking lots that are empty.
Macerich malls loaded with bankrupt tenants due to the fact they strong arm tenants to get into their top tier malls by leasing spaces in their lower tier malls. Then they have to deal with the new shopping demographic the shelter window shopper, massage chairs filled with homeless people sleeping in them.
Hotels turing into homeless shelters has been going on for several years now and they are packaged in different categories to mask the fact they are trully shelters. Transition housing, section 8 housing, work release housing, men’s housing, battered womans housing, then these people have nothing to do but contribute to the window shopping network. Which negatively impacts the actual people who enjoy shopping and contribute to keeping these stores in business.
Some developers have also built hotels on the disguise of apts. It’s an easy way to built residential in a zoning that doesnt permit it.
$218 million loan backed by the 1.28-million-square-foot Crossgates Mall in Westmere, a suburb of Albany, NY.
Anybody who would invest $200 in a mall in Albany, New York deserves to lose all their money.
I predict that ones of the things that will happen with the disappearance of brick and mortar retail is that most consumer brands will become homogenized and lose the status/style that differentiates one from the other and creates the “I will pay extra for the famous brand,” dynamic. Big fancy stores are one of the ways a high flying brand like Nike or Apples differentiates themselves from the more generic competition. Another is sports, concert, live venue promotions. Covis-19 and shop-online has thrown all these things out the window. We may see a shift to generic shopping choices based on Amazon or Walmart’s whims. This does not bode well for the brands like Nike that are built on selling cheap stuff made in the third world for high prices based on brand differentiation. It may all just become cheap stuff for cheap prices.
Nike sells quality cheap stuff. There is also the cheap stuff with no quality. Stuff that you have to buy new within 6 months while with Nike the only reason why you would need a new one is because the sole has been worn out
In 2018, the United States had the highest square footage of retail space per capita worldwide at 23.5 square feet per person. Canada and Australia followed behind with 16.8 and 11.2 square feet, respectively.
That was before covid, basically retail space was already overbuilt, now along comes covid and compresses what would have been a normal reduction over time into an 18 month squeeze.
Real down towns with angle parking, a good cafe/bakery, maybe a real butcher shop and actual retail stores are a good experience. My daughter lives in such a place. The malls (which we pass on the way) are freaking dreadful, from parking to ambience. Malls have created online shopping imho. What were they thinking?
Yes. Greenwich, CT and Naples, FL are two such examples of very nice downtowns.
The one percent have been able to keep others out of these places.
A butcher shop does not belong between mall type retailers. What you describe is a down town that competes with a supermarket, not a mall and can’t be done outside of some very special circumstances.
All mall retail are “butcher shops”. Guess who are the lean cuts.
Malls force the shopper to conform, not to give choices. We commute to Marin to shop. The Macreich owned Village in Corte Madera is high end bankruptcy, Macy’s, Apple Store, Microsoft Store, Neiman Marcus, wealthy trophy wife territory.
Across the freeway is the more middle brow Corte Madera Town center with it’s gas station, REI, Safeway and ridiculously narrow parking places that force people with nice mid-sized and up cars to straddle two spaces, or to go elsewhere.
Still those malls, plus the authentic small town businesses in Marin, are far more desireable than shopping and parking in the city.
It’s kind of funny that actually with the on-line retail business that a lot more square footage is being built, but instead of store fronts it is warehouse fulfillment centers. Creative destruction just like in the text books.
The fact that US retail space ha been overbuild is not something new. It was also true 20 years ago and it would not surprise me if it was also true in 1980 or 1960. All countries have to deal with a large shift from mall retail to web retail and it everywhere painfully for retail property owners and local government.
Will Judy Shelton next run The Fed???… PJS
Fed is about done. Maybe yield curve control to squash long term rates down. It’s up to Congress now to spend like drunken sailors for make work jobs or reshore the industrial base to N. America and get the inflation rate to 3% or 4%.
Hope so. Own gold miners
“Debts that can’t be paid *won’t* be paid”
“A financial crisis is a break in the chain of payments”
— Michael Hudson
Sure the U.S.A. Titanic is on the Niagara River and headed for the Falls. But not to worry: The Fed is sewing a giant green parachute. Parachutes work for people, why not ocean liners? Isn’t that why dollar bills have so much cloth in them?
Yes Our Dear Leaders can still take the Welland Canal and bypass the Falls; it’s not quite yet too late to implement a Debt Jubilee, but that would require a drastic change in philosophy. Real Men would sooner burn the whole thing than abandon our magnificent Sink or Swim social systems.
So please do carry on about how to minimize real estate losses and how to profit from the unfolding catastrophe. The *thirty million* workers with no stable income and soon no housing or food will either figure out how to live on the street — or not.
We don’t need them anyhow. The past few months have shown it doesn’t take many millions to do what needs to be done for survival of the millionaires and the billionaires.
Everybody else can go suck eggs, or rocks if they can’t buy eggs…
As for me, I’ll just keep repeating a comforting motto while the ship is going over the falls:
Greed Is Good!
Greed Is Good!
Greed Is Good!
Give it 10 to 20 years. And then do a Netflix show about the Golden Age of Malls.
Malls will come roaring back. You can’t beat nostalgia.
It would be interesting to estimate the total approx loss in value of commercial space, malls plus offices.
I would venture that it wipes out a lot of the stimulus and that, net, the economy is deflating despite the Fed.
Private Debt to GDP is 220%
The Fed’s still got a long way to go if it wants to stall deflation.
Here are few things the gov might try:
1. Forgive student debt
2. Green new deal
3. Cold war build up with China
4. Housing credit
5. Cash for clunkers to go electric
6. Universal healthcare
7. Universal childcare
8. New highway system
9. New power grid
10. Passenger rail
It’s easy for politicians to spend money and destroy real capital if Fed keeps financing cost near zero
I am amused when I see a list like this. A lot of the things we’ll need to do the above will need to come from …. China.
7 months into the pandemic and most of our PPE still comes from ….. China.
All China needs to do is cut off supply of our medicines, and it’s goodbye my love.
Bottom line is these malls and commercial property represent an incredible amount of non performing loans. The sad part is most of these loans are not being held by the people who wrote them. Instead most of this bad debt now is held by pension funds, and bond funds. There are a whole lot of people out there who’s retirement money is going away quickly, and they do not even know it.
Forget AOL, Yahoo and hotmail. The internet revolution..Times have changed and things are totally different after some 20 years. Its different this time now. This is the age of insta, youtube and twitter. Just make videos of these blogs (not those ten minutes) and post them free on every platform. Your blog has more grasp but has no reach. Blogs are Ok to these old timers. Embrace the Gen Z’ Zoomers and the hustle economy…
Take the red pill…
Adding to the discussion about moving of of the cities.
The small towns will need need to change from the current model of imitating cities with the hollow centers. My experience with small and large towns and suburbs is that the small town downtown needs support financially and politically. What happened the past years is that the superstores and strip malls stripped business away from the downtowns. Life in the smalltown downtowns need parking, lots of parking and easy access to create a center space worth going to and strolling in.
Given the modern shopping experience, the viable businesses for a downtown area are bars/restaurants of varying grades and types, services like doctors, dentists, barbers, stylists, and frivolities like candy stores, rinks, bowling alleys, toy stores, mini department stores.
Modern zoning has fought these trends due to the influence of large businesses and franchises. This is likely due to the consolidation of banking that removes local capital to money centers.
Big cities just do not scale in a human fashion. With packed in people, come the depression of the human spirit.
It would be interesting to see the trends in condo sales in the suburbs. It seems that people in the US are moving to the smaller centers. Older people like some folks that I know living in large centers, find themselves unable to venture out, even without Covid.
As long as King Dollar is the reserve currency, this joke will continue. Interesting to see what gold does as it moved over 1900. Wait and see.
Regarding malls, I have always thought these can be converted to living areas (condos, lofts) and have small retail businesses below. I read that this is a popular living scenario in China. The retail businesses are below these large apartment buildings, sky scrapers, etc. In fact, I heard something on the radio that some REIT’s and mall owners area considering this.
JK,
I also think malls could mimic Asian styles of living. Only they could be turned into Singaporean food stalls or have a beer hall, etc. after the pandemic. At the local dead mall near me, they have converted some of the space into offices for local government. There is so much unused commercial space for rent around here. Two years ago, developers decided they need to make money so they chopped down more trees to create empty strip malls. Unmitigated growth and cheap money lending has allowed this farce to go on unabated, so maybe a downturn will make them think twice, although I doubt it.
As an Amazon delivery driver, I am no fan of Amazon.
Amazon has created a unique retail environment where the retailer that loses the least wins. I keep reading comments that retailers like Walmart, Target, Home Depot are now offering better prices with similar delivery time frames than Amazon.
To me, the sad reality is these companies are doing so at a huge loss.
Amazon loses very little on a delivered product while the loses for companies like Walmart etc, are likely substantial.
Two of the biggest advantages that Amazon implements is that they have their own delivery network as well as the prime membership, the fees of which are used to absorb some of the delivery costs.
Walmart etc must use Fedex, UPS and USPS. Fedex isn’t going to deliver a product at a loss so Walmart can compete with Amazon. Walmart must absorb the loss to stay competitive with Amazon.
Amazon has created an ecommerce environment where the one that loses the least wins.
I worked for a large DSP, operating in 6 states. The DSP lost their contract with Amazon for questionable reasons.
Breaking up the a large DSP into 6 smaller DSP has many advantages.
The rational offered was that the local DSP would be more able to focus on meeting Amazon demanding service level agreements.
The other brilliant advantage, is that the DSP’s can never unionize.
Talk of unionization is so easily addressed, just remove and replace.
What is a DSP?
Digital Signal Processor? That’s the answer I get when searching.
Don’t assume people know what you do. Spell it out at least once, por favor!
My guess is distribution service provider but it is definitely a guess.
So the p is partner. As if two men and a van are equal to Amazon.
Amazon’s delivery network is broken down into very small DSP’s, delivery service partners. I would estimate that 90+ percent of all packages are delivered by DSP’s.
Does this mean that it is not an auspicious time to invest in commercial REITs?