The recovery as it were, after everything went to heck but didn’t.
By Wolf Richter for WOLF STREET.
San Francisco is one of the most touristy cities in the US – both for leisure and for business – and it is also a tech and social-media center, a startup Petri dish, and the epicenter of working from home. During the Pandemic, the city has lost large chunk of jobs and a significant number of its residents. So here is an anatomy of the San Francisco economy where it currently stands, based on a report by the City of San Francisco’s Office of Economic Analysis and based on some data from other sources that I added to the mix.
Despite the loss of jobs and population, the remaining residents in the city are doing what they’re supposed to do as good consumers: They’re spending money. By May, credit card spending had fully recovered and was up 5% from the pre-Covid baseline in January 2020, according to credit card spending data, seasonally adjusted (Chart via the Office of Economic Analysis, citing data from the nonprofit Opportunity Insights and Affinity):
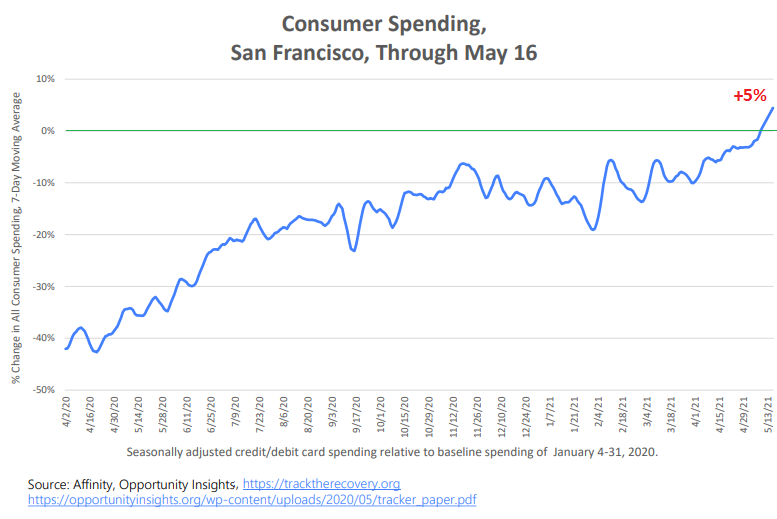
So locals spent 5% more with their credit cards than they did before the pandemic – and this was just inflation since CPI jumped 5% year-over-year in May. And they’re spending less in brick-and-mortar retail stores, many of which remain shuttered, and more online, and they’re also spending at restaurants and other leisure activities.
Small businesses: restaurants v. brick-and-mortar retail.
There is now a thriving restaurant scene. Indoor dining is back, and now there are about 1,500 “parklets” where restaurants have created outside-dining areas on curbside parking spots, wide sidewalks, back patios, and public areas. Some restaurant streets are closed to traffic at night, and there have never been so many people visible on the street, milling around and sitting around in these parklets, as now. The whole ambiance has changed.
Restaurants with parklets now have more tables than they did before they built the parklets, and they can accommodate more business than before. And all kinds of new restaurants have sprung up.
But brick and mortar retail stores are in deep trouble. The sight of shuttered stores and “for lease” signs are everywhere. Nail salons and other services-based businesses are sprouting, but brick-and-mortar retail was already in trouble before the Pandemic, and so many stores were vacant and forming a blight that the city imposed a vacancy tax to incentivize landlords to find tenants.
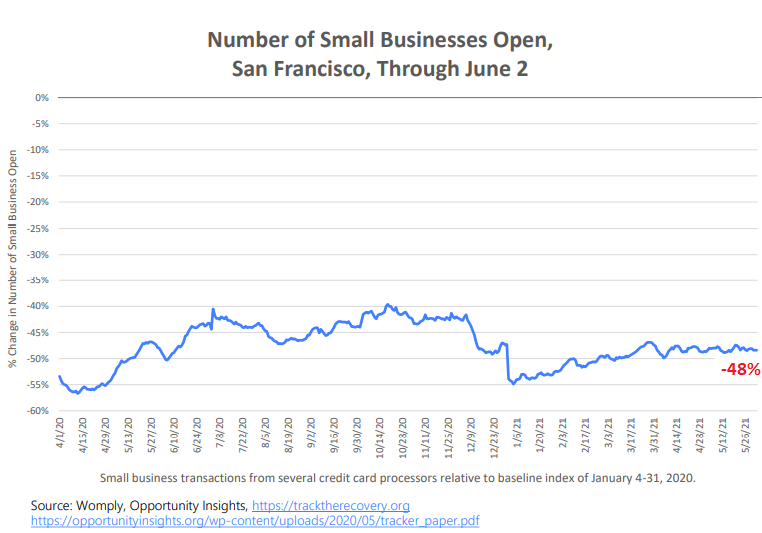
As of June 2, 43% of San Francisco’s small businesses remain closed, compared to the already beaten down baseline of January 2020 (green line), based on payment and payroll data from Opportunity Insights, cited by the City’s report.
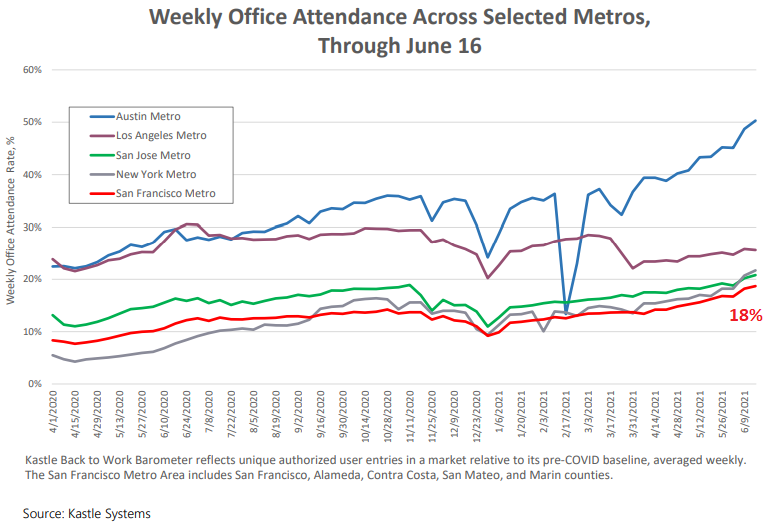
Working from home and not going to the office.
Working from home is huge in the San Francisco metro, and office attendance is still minuscule. According to data from Kastle, which provides electronic access systems for office buildings, office attendance as measured by people entering offices in the five-county San Francisco metro (red line) was at 18% of the level in January 2020, meaning office attendance was still down 82%, but creeping up. For comparison, in Austin, TX (blue line), attendance is at about half the level compared to January 2020.
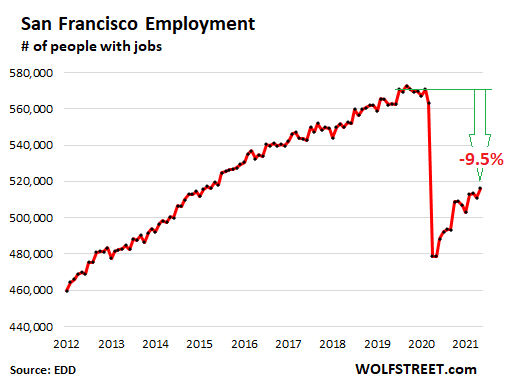
Employment plunged, then recovered only some.
The number of residents in San Francisco who are working took a massive dive in April 2020 and has only partially recovered. In May, the number of working people was still down by 9.5%, or by 54,500 people, from February 2020, according to data from the California Employment Development Department (EDD). And as we’ll see in a moment, some of those people have left San Francisco:
The leavers and the stayers.
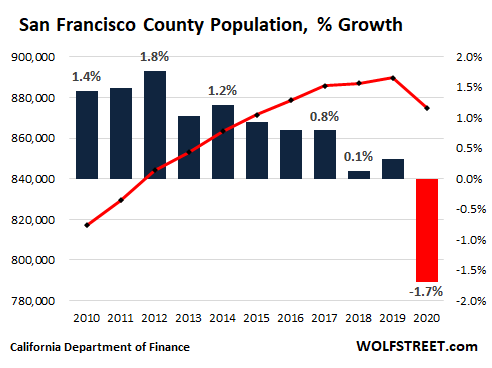
In early May, the California Department of Finance released its annual population estimate. By the end of 2020, the state of California had lost 182,000 people compared to a year earlier, the first population loss since the data had been tracked. San Francisco lost 14,800 people or 1.7% of its population (red column), now down to 875,000 (red line), the lowest since 2015:
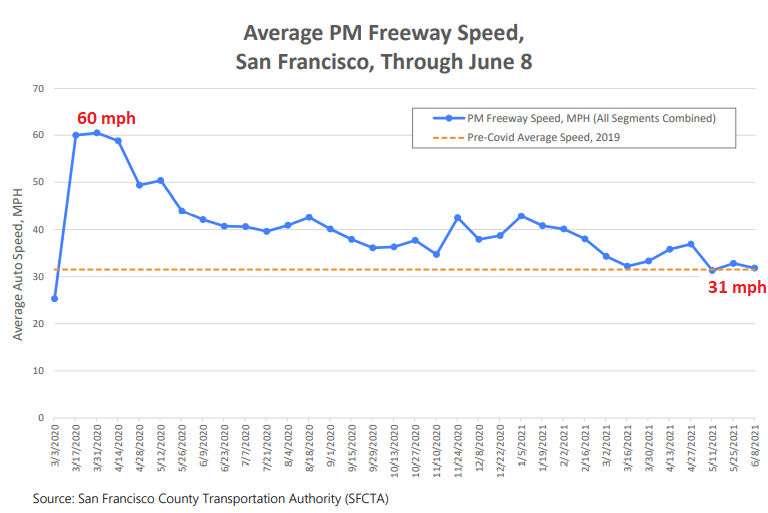
But road traffic out the wazoo again.
Traffic across the Golden Gate Bridge into San Francisco in May was down only 15% from the 2019 average. Traffic congestion on the freeways is back, and average speeds have slowed to pre-Covid averages of 31 mph, down from 60 mph in March and early April 2020. Lots of people are driving who had been taking mass-transit. And plenty of tourists from other parts of California or the US are driving into San Francisco. The weekend congestion is back. We live on a busy street, and it’s busy as heck, especially on weekends:
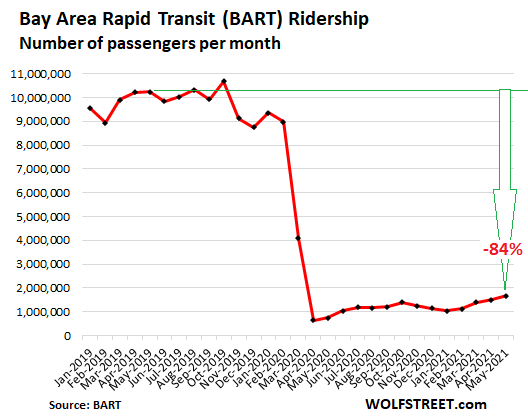
But almost no one is taking mass transit.
The Cable Cars are still shut down. Buses and streetcar lines operate at reduced levels. Ridership on the Bay Area Rapid Transit (BART) system, the train system that links the East Bay to San Francisco and Silicon Valley, was still down 84% in May from May 2019. When people do go to work, they’re driving:
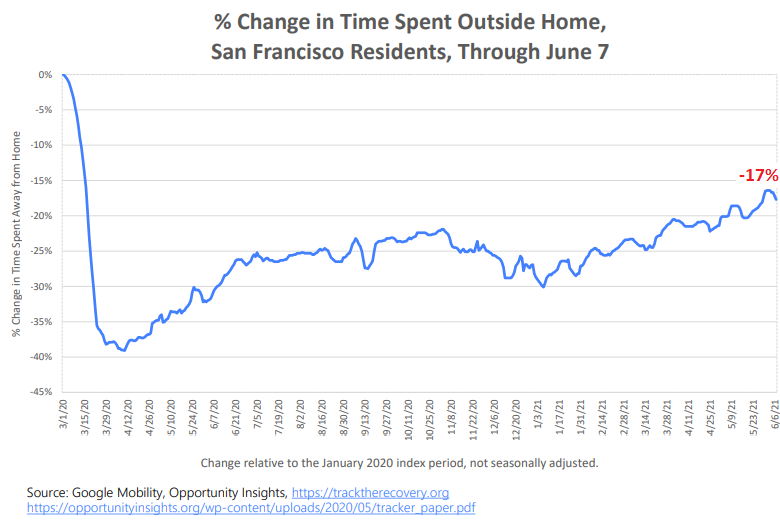
Time spent outside the home despite working from home.
Despite the prevalence of working from home for office workers, and the near ghost-town atmosphere of the Financial District — though it’s much less so now than last August when I documented the ghost town Financial District with photos — many businesses are open and require workers to be there, from restaurants and repair shops to construction sites.
In addition, locals have discovered the beauty of outdoor areas, the parks and shore line while tourists were largely gone. I have never seen so many people swim in the Bay while pools were closed. Locals were doing lots of stuff and getting out. But many of them were just not going to work, but were working at home or were not working at all. Now the swim teams have returned to heated pools. But people are still not going to the office (chart via the Office of Economic Analysis, based on data from Google Mobility and Opportunity Insights):
International tourism and business tourism are still dead.
Tourism, a huge industry in San Francisco, is still way down. The crucial tourism from Asia is still dead, and business tourism is also still dead. But domestic tourism is thriving, and these people drive from other places in California and from other states into San Francisco, as demonstrated by the traffic jams on weekends. But far fewer people are flying in.
According to data from the San Francisco International Airport, the number of people getting on a plane in April – such as business and leisure tourists going home, and locals heading out – was still at 31% from the 2019 average. Part of this is the collapse in traffic between San Francisco and Asia (chart via the Office of Economic Analysis):
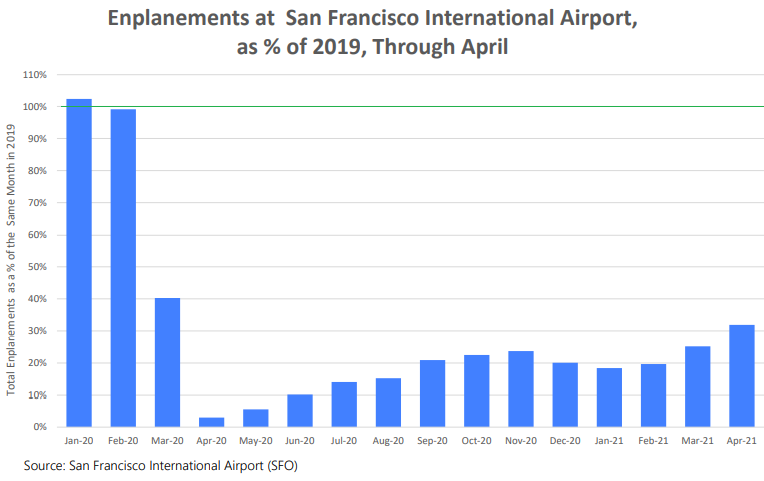
Hotels reopened, and some folks are showing up.
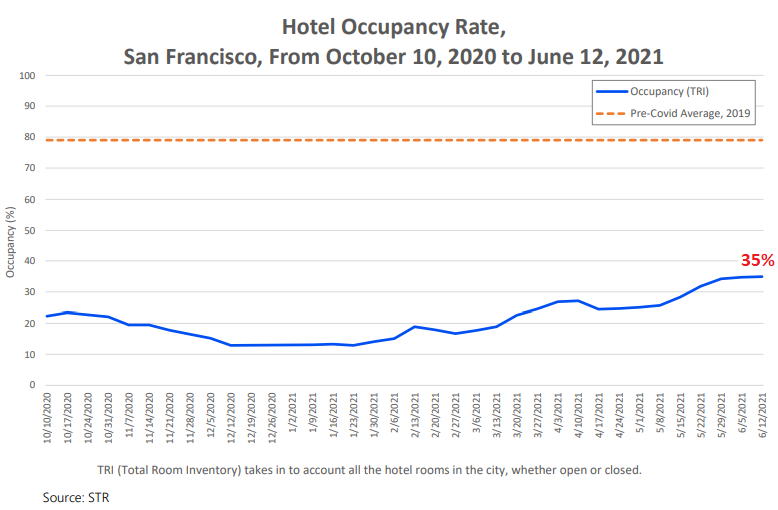
The average daily room rate has risen to $160 per night. But that’s only about half the average rate in 2019 of around $319 a night.
And hotel occupancy, which in 2019 averaged around 79%, was still only 35% in May. This is figured of total room inventory (TRI), which counts all hotel rooms whether or not the hotel had re-opened (chart via the Office of Economic Analysis):
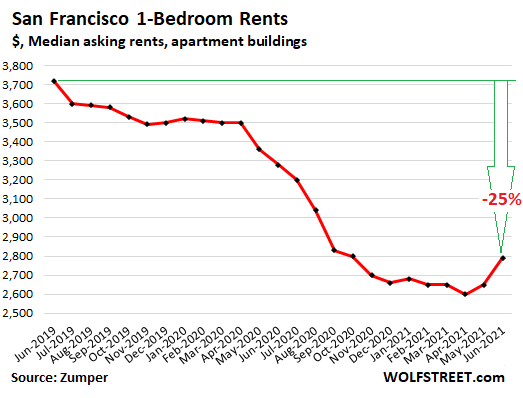
Asking rents plunged 30%, and now there’s price discovery.
So there are fewer people living in San Francisco and fewer people have jobs, and apartment vacancy rates are high, and there is a huge amount of churn, with tenants trying to get better deals and nicer apartments. This has been going on for over a year.
In June, the median asking rent for one-bedroom apartments was $2,790, according to Zumper, down 25% from July 2019, after having been down as much as 30%.
But these are asking rents. They’re a way for landlords to find out what the market will bear. If the unit sits vacant long enough, they’ll drop the asking rent or offer other inducements, such as two months free. Asking rents are not actual rents or effective rents. They’re advertised rents; they’re the rents at which a landlord is trying to make a deal; they’re a form of price discovery, and in uncertain times like these, they can be all over the place.
So this is the economy of San Francisco. Fewer residents, fewer tourists, fewer jobs, fewer businesses, a still dead Financial District, lower rents, lower hotel room rates, near-empty BART trains, and lots of closed stores, but busy restaurants and lots of spending by the people that hung on.
Enjoy reading WOLF STREET and want to support it? You can donate. I appreciate it immensely. Click on the mug to find out how:

![]()
I was on SF in mid May. I have never seen people so happy to be outside. I went to breakfast with my daughter the first day and people were sitting outside wearing wool hats and parkas. Some were wrapped in blankets, but doggone it! – they were OUT!
And there was the guilty pleasure of having the city to yourself without tourists everywhere, knowing that you needed them back.
I was visiting from my adopted country, Texas. We had already been pardoned by the governor much earlier. Not that we took it seriously anyway – barbecues were automatic social distancing. No one can catch covid from smoking a brisket or by eating it. You could also socially distance by going to your hunting lease. You could even pretend to be in SF by sitting in your hunting stand at 6 am freezing your butt off and enjoying the lack of tourists. And it has always been difficult getting too close while wearing those big hats.
There was also an air of uncertainty in SF. The rules didn’t seem to be clear. People wearing masks and people not wearing masks would sort of covertly eye each other wondering who was wrong. Kind of like when you’re driving in a light rain and checking to see who had their wipers on or not. You don’t want to be the only person doing either.
Then there was the fukitol crowd. No masks, let’s shake hands, we’re spike protein factories now, hear us roar! Let’s eat outside – it’s almost 55 degrees. You can borrow my blanket.
Michael Gorback
“People wearing masks and people not wearing masks would sort of covertly eye each other wondering who was wrong.”
Interesting question ??
I suppose the only answer to that is to ask if a virologist working on a semi-nasty virus would work on it wearing a simple cloth or paper mask. You could also ask, if you were working on a semi-nasty virus, would you trust a paper mask to protect you. If your anwer is no to both questions or even one, then you know who was right.
Well, I am an immunologist with thousands of hours of BSL3 time working on live viruses, and frankly, your straw man false equivalency is tiresome. Too tiresome for me to even dissect at this point of what has been a tiresome 18 months of uninformed people spouting uninformed opinions. So, I’m just gonna go do something productive now rather than getting into this again.
Rather than having a patronising hissy fit, why not let us know in a very few words your expert opinion?
Are commonplace masks worth it or not, indoors and out?
A friend who is also in immunology, and actually rather distinguished (Cambridge University) has given me his considered opinion, and I for one would value yours.
Xabier. So what did your friend say? To throw your question back at you.
I have used respiratory protection for chemicals and trained people on that for decades in my humble occupation.
If one searches, there are examples of engineering labs that have been publishing data for decades on the subject of respiratory protection in chemical and medical applications.
As usual, anecdotal info is used to counter quantitative data. No piece of gear is perfect partially because people using it are not perfect. Example- you can have the best mask, and if you contaminate it, you will not get protection.
Masks help, and the procedures for using varies. An “engineered/designed” mask is optimized for exclusion of contaminants and enough flow for intended purpose. If you use two of those you will not succeed because of air flow problems. If you use a piece of cloth, you can use two and get enough flow, etc.
What is called a “fitted medical mask” is supposed to be the best against viruses. There are youtube videos of medical specialists talking about these.
One has to want to know and make the effort to search for the info. You will not get it in the popular media.
No one got the flu.
Hahaha! It was driving me crazy and I figured with dropping the mask requirements I’d heard the last of it, along with “You can’t force someone to wear a mask”, “You can’t force someone to get vaccinated”, and “I wore a mask and got covid anyway”.
But yeah they can force you to get vaccinated since the Supreme Court ruling in 1905. And if you think nobody can make you wear a mask try not wearing your seat belt.
Common Anthony, you have an axe to grind, we get it. But there is credible evidence that masks can help reduce the spread of an airborne virus.
Face masks effectively limit the probability of SARS-CoV-2 transmission
Science 25 Jun 2021:
Vol. 372, Issue 6549, pp. 1439-1443
DOI: 10.1126/science.abg6296
Anthony,
This discussion is BS. San Francisco has had the lowest, or one of the lowest, infection rates of any major city in the US though it was among the first cities to get the virus. Prevention measures, including broad adherence to mask rules, saved lots of lives.
Michael Gorback, a doctor, understands the importance of masks, though YOU might not.
What he was talking about was that in May, mask requirements were being lifted for fully vaccinated people. And many people continued to wear masks because it’s free and doesn’t hurt and can save lives. What’s your problem with that???
Totally agree: masks save lives. There is also a lot of information online about which masks are most protective. It’s been possible to get N95s for quite a while.
Separately, there was a good Ars Technica article explaining the CDC’s perplexing May statement about masks: not based on science; rather, the CDC was trying to manipulate the non-vaccinated into getting the vaccine.
Good luck reinstating the mandate .
We saved a lot of lives here in Montgomery County, MD. We are the lowest in the country. We beat SF. People acted responsibly for the most part. Now its time to get back to work and get the kids back to school.
Masks help, but are not perfect, like most things in life. It’s like taxing the extemely wealthy to make them pay their share. Sure, it would not solve the deficit, but it sure would help. Straw man argument it was.
It’s hard to believe this kind of argument still exists.
Masks, unless N95, are NOT for your personal protection. They are to protect others from large droplets that are spewed by the person wearing the mask.
That’s why (well, one of the reasons why) people are angry at Fauci. At one point he told people not to bother with masks since they were not protective. Later on he pushed for masks, but for the reason cited above: they block transmission from the wearer.
So your mask protects me and my mask protects you.
Fauci- for those of us in the SF area during the AIDS outbreak, he is a famous MD. I started last year by telling people to listen to him.
He messed up the communication so many times, has emails about wanting to create super-viruses, insisted on funding the lab, and wants to make money on a tell-all book.
He really messed this up. Now I ignore Fauci.
That’s not why Fauci initially told people not to wear masks. He told people that because there was a critical shortage and healthcare workers needed priority. Fauci should have been honest and told the public to make their own until the shortage was addressed. Instead, he elicited mistrust and confusion.
Hei guys, don’t question St. Fauci, because if you do, you are questioning SCIENCE!!!
ROFL
We’re about a year and half into the pandemic and these notions still persist. It’s incredible to say the least.
Masks don’t protect the wearer. They protect the others from you especially if you are infected with Covid. If you know you are sick with Covid or with the flu, what the hell are you doing out in the public infecting other people. Stats show that 80% of the people that got Covid were wearing masks at the place of infection. END OF STORY.
P100 half mask respirators are likely close to 100% effective against covid and variants. I have used them for years in industry to protect my lungs. They are affordable – about $50 – and reusable almost indefinitely in low particulate environments. Should have been mass produced and deployed everywhere in confined spaces. Would have stopped the pandemic.
“I suppose the only answer to that is to ask if a virologist working on a semi-nasty virus would work on it wearing a simple cloth or paper mask. ”
Paper masks are good for blocking sneezes but they won’t protect you from the virus. Most people have little education in the sciences and can’t comprehend what’s happening at the molecular level. Unfortunately our government is now capitalizing on this ignorance to get people out of masks and shopping again.
Viruses mutate and we know that you can still carry the virus even if you’re vaccinated. So the only true way to get rid of this thing with the current crop of vaccines is to wear masks. My guess is that that our corporate masters want to make this a long emergency that keeps people in constant fear and dependent on the government for their next dose of vaccine (what all drug dealers do).
Still, I don’t know how San Fran will keep going with 43% of all small businesses closed. Sounds bleak.
Vaccinated people are unlikely to transmit covid. What is called sterile immunity is rare. If you have polio vaccination you are safe gut you can still carry the virus in your gut.
Even in largely vaccinated populations, dropping vaccination rates can cause resurgence, as we saw with measles in 2019. Thanks NYC!
The best measure for covid is to just go ahead and ride the needle.
May data show that there were 853,000 covid related hospital admissions, of which 0.1% were in vaccinated people. 99.9% were not vaccinated.
More than 18,000 COVID-19 deaths in May, of which 0.8% were vaccinated. 99.2% non-vaccinated.
Can it get any clearer? Get vaccinated. Masks and social distancing are nothing compared to vaccination.
@Michael Gorback
You missed the point. We’re trying to kill off the old strains and prevent the evolution of new strains. Only a combination of masks and vaccination can do that. You are also assuming that these COVID vaccines are on par with the polio vaccine which lasts for many years. Most experts stress the current crop of of vaccines will only likely last 6-9 months, but that is still up in the air.
Right now the authorities are holding back the most promising vaccine we have -the Novavax vaccine. Good masks always work against all current and future variants!
P.S- “The World Health Organization (WHO) Friday recommended continued COVID-19 safety protocols even for fully vaccinated people, due to the continued rise of the highly transmissible delta variant.”
There is no way short of the sun going supernova of “getting rid of this thing” as it is now ENdemic. The virus exists, like the bacterial bubonic plague, and it will mutate and pop up occasionally and kill a few people.
We, the arrogant species we are, think we can get rid of it. We have to accept and deal with it.
Bobby Dale- A very refreshing statement, “We, the arrogant species that we are..” Thanks.
Most of the commenters on the Covid Subject here ARE arrogant, (especially those that hold various levels of “knowledge tickets” in the Medical Industrial Complex) in that they did NOT learn they understand very VERY LITTLE about a 4.5 billion year chemical game. Still, a ticket entitles them to speak like they do, and make more money.
Here is one of my favorite virus articles, only the first section needs to be read.
https://pubmed.ncbi.nlm.nih.gov/30250470/
If saying all this makes me arrogant, and it likely does, I admit to it. I also admit to having hated parts of this culture someone else invented and stuck in my brain for most of my life. But I do like and value my body, even my brain, to the extent that it has allowed me to keep questioning, exploring, and learning and UN-learning as I finish out my 83 years of existing, or whatever it ends up being.
Oh yeah. I WILL wear an N-95 every time I leave my apt (except when driving) for the next 2+ years if people keep dying from it, even though I’m pretty certain I have had it, and hope the blood test I get next time I see the Doc is (accurate) confirmation.
I also totally believe in GOOD science and GOOD scientists e.g., curiosity driven, not money driven.
Robert,
“Paper masks”
You make it sound like a pejorative. But there are several types of common and well understood filter materials, including a randomly layered mat of fibers (what you called “paper”).
The air filter in your car a “paper” filter.
For the past 15 years, we have used two big HEPA (high-efficiency particulate absorbing) filters at home to filter out allergens, and they work wonderfully. HEPA filters filter out virus as well, including Covid. And they’re “paper” filters = a mat of randomly layered fibers.
The randomly layered fibers as filter material has been well understood for many decades. They are usually made of polypropylene or fiberglass (air conditioner filters), and they come in all kinds of designs and for all kinds of applications.
You can design these filters to filter out smaller particulates, in which case they’re harder for air to pass through. So for filters that you put over your breathing apparatus, you have to make compromises so you can breathe. N95 is about all you can breathe through.
An N95 is also a “paper” filter, but inferior to a HEPA. But a HEPA filter is too hard to breathe through, unless you have a large filter surface, which makes it awkward for a face mask.
Wolf, you’re right on being a stickler for words, but as a person with a scientific background I say what I mean. Paper (being nothing more than cellulose based fibers), is vastly inferior to the melt-blown polypropylene fibers found in n-95 masks and HEPA filters. Yes, HEPA, is often made from mats of synthetic polypropylene fibers with the noted exception many of these synthetic materials can maintain an electric charge so as to better attract particles.
Paper does not mean “a mat of randomly layered fibers.” In fact paper is not really a scientific term but a broad description of many types of cellulose based materials. You would never really use that term in a published article, except in the widest sense.
I have nothing against paper anything, and I’d make masks out of Broccoli if I thought it could block COVID. Just used ‘paper mask’ as an example of a cheap, marginally useful type of mask.
Since I “damned” the Medical Industrial Complex, here is a good example of the crapp that goes on at the hospital/insurance part of the whole biz.
https://khn.org/news/article/surprise-bill-iv-push-hospital-unbundling/
This has nothing to do with Kaiser, the HMO. It is funded by the Kaiser family (who were just into making steel and things out of steel) but nonetheless had a part in starting “Managed Health Care”, which (like everything else) is ALWAYS best done by the more “efficient” Private Industry, as every pre-programmed government bureaucracy hater knows and says as much whenever possible.
Incidentally, a hospital’s billing codes are proprietary (considered part of management’s “managing secrets”).
We need single payer like the rest of the developed world, healthcare is a RIGHT…..even if it is at present largely full of money making “for profit science”.
But they still can help out a lot of people, just not anywhere close to as many as they claim they can.
NBay,
What we really need is for a few thousand of these hospital administrators, and the decision makers at the PE firms that own these hospitals, to get sent to hoosegow for a few years or more. The RICO Act or other laws should be applicable here.
I agree. But I bet enough laws have been lobbied thru by these criminals that any DA would find prosecution prohibitively expensive if not downright impossible, not to mention gutting of his and all other “wasteful” government resources.
See GFC aftermath, only one major player was prosecuted and he turned himself in.
Are you an epidemiologist?
If not, I’ll just file your “opinion” where it belongs…in the garbage.
Nice piece of trivia. According to online articles San Francisco is cold. They’d be warm, if they were in LA.
“I was visiting from my adopted country, Texas. ”
So when does Texas go back to being it’s own country? maybe all those Californians in Austin will move back to California. Then I’m ready to move down.
Come move next February when the temps are below 0 and there is no electricity.
So you are saying the Californians brought their brownouts with them?
Hopefully soon. Then we can have our own internet and money. LOL!
To paraphrase the Reeses commercials, “Keep your California out of my Texas”.
Austin was already like California. The immigration has only made it worse. The last thing I’d want here is California style voting and policies.
Don’t put it past Texas to build its own wall – around Austin.
I like watching those doofus buffoons strutting around in their 10 gallon cowboy hats. Cracks me up every time. Imagine…grown ass men walking around making total jackasses of themselves!
Like George Carlin said “It’s not even Halloween. The closest “Tex” ever got to a steer is when stopped to to take a crap at an Arbys.”
Watch the next hurricane that hits Houston. All those anti-govt “Don’t mess w/Texas” crybaby snowflakes will be wailing: “Where’s FEMA?!?! FEMA come help us!!!!”
The best hypocrites you can find….
nodecentrepublicansleft, if Texas is such a bad place, explain to me why all the California residents are relocating there?
Anthony A.
“explain to me why all the California residents are relocating there?”
Not all. There are still a couple of us fossils hanging on here, holding down the fort. 39 million, to be more precise :-]
Yeah, I’ll try to suffer it out here, too.
BTW, the only thing I can think of offhand that is nicer about Texas (I’ve driven around most of it) is that when oncoming traffic sees you are speeding, they flash their lights to let you know they passed a cop hiding behind a billboard or something to warn you. Last time thru was late 70’s, so I don’t know if it’s still done there.
Although now that I’m thinking about it, it seems kinda odd for a “law and order” State.
Oh my, Michael, you are in danger…. These are all potential superspreader events, all these unmasked in TX are going to make you sick. Hope you are at least vaccinated, although the efficacy against the D and D+ variant is really TBD. And what happens when there is a further mutation.
?
I love your ‘little story’ ?
We the people, when we are good, we are magnificent.
“we’re spike protein factories now”
Why isn’t someone selling that as a T-shirt in Union Sq. or Fisherman’s Wharf?
Or a BEER MUG?
Somehow Nixon’s declaration in 1971 that we’re all Keynesians now didn’t make it to a T-shirt either.
If Martin Luther were alive today, do you think he’d nail 99 T-shirts to the church door?
Please state any evidence that these mRNA injections are doing anything at all to genes. I would love to see it.
Wait, how did San Francisco experience the stimmies fueled inflation?
Most folks out there (particularly the ones I know), didn’t qualify for any of those fresh greenbacks.
Most of the folks in the city are part of the 6 and 7 figure crowd, didn’t lose their jobs, and didn’t receive all that free unemployment payouts.
And considering most folks in the city have pets, rather than children, I can’t imagine the child tax allowance suddenly pumping in the money.
But strange, maybe it was all pent up demand.
Maybe folks were saving money during the quarantine.
Maybe following a blitzkrieg vaccination push, all the money was literally rushing for the exit door.
Maybe, even without stimmy money.
If only we could find a counter-factual, looking for a country (Canada) (Australia) or an economic bloc (EU) that still gave out mad amounts of social program money, didn’t blast everyone with vaccine in a matter of weeks, and then douse businesses with unrestrained demand.
In theory, business owners could have kept prices low, just to make sure these contrived charts didn’t jitter.
But I guess we can’t shame the people with actual power for price gouging when the opportunity arrives.
Let’s talk about “buyer’s strikes” instead, as if they were collectively organizing a civil rights campaign.
davie,
“Most folks out there (particularly the ones I know), didn’t qualify for any of those fresh greenbacks.”
Yes, there are quite a few people here who didn’t qualify. But LOTS of people who DID qualify. Median household income is $112,000. Median per capita income is $68,000. Meaning half of the households and people made less than those median income figures.
Plus, lots of people got forgivable PPP loans, given the importance here of contract work (coding, engineers, etc.), startups, small businesses (such as law firms), etc. I looked at the SBA’s list of PPP loans by zip code. And it’s amazing how many PPP loans there were by zip code. That too was stimulus money, but for a lot of these people it was serious money, 10s of thousands or 100s of thousands of dollars. That’s where the real stimulus money was.
I suspect some of the recovery was due to stimulus money in one form or another.
If you look at net national savings we haven’t had a recovery. We have been trending down from more than 10% to around 2% with multi-year trend still down. If you save $10K and govt borrows $10K then national savings is zero. You need savings to increase long term standard of living.
I still say we are under an illusion of recovery as it is fueled by government policy of debt. We probably would have been better off to have had limited and targeted spending on those who really were affected by covid instead of blanket money spraying all around. Now demand is too hot for supply so prices going up.
Government had no good ways to inject money into the system before this event. Government struggled for how to get money funded to small to medium business and that program was PPP. Was involved with the regional banking system as that was setup. It was changing on the hour by the minute as we deployed this. We now have ways and methods for money to get out to small to medium businesses that didn’t exist. This fundamentally changed and built a framework for future money deployments in mass
1) Dr Faust : keep America comatose until we know what we don’t know.
2) But what if the patient will not wake up. And what about the brain damage.
3) SF number of small business open : (-) 52%.
4) NYC office attendance : (-) 80%.
5) International business travel : (-) 90%
6) BART ridership : (-) 84%. Parking lots are thriving in sunny summer days near SF Bay.
7) Adjust to @ 5% inflation, 1BR rent : (-) 40%. Since apartment prices stayed about the same vs houses, 1BD yield : ($3,800 x 0.60 x 12M)/ $1M(?) < 3%, better than the stock markets.
Excellent!
An economy in a forced coma, probably waking up to find itself partly brain-damaged.
Sounds not at all unlikely.
That whole sectors of the economy will have to be eliminated anyway to to the growing energy/resources crisis, and others rapidly digitised to meet other strategic aims, perhaps makes the putting into a coma condition easier to understand……
I like the New York City layout. It is basically a series of small towns populated by many small businesses, surrounding large corporate facilities, like Wall Street and its environs. You got big, but you also got neighborhoods. Is that layout now irrelevant? I am skeptical that suddenly the entire world changed fundamentally. There’s a lot of churning going on, which is understandable. But I doubt that it is permanent.
I wonder if 43% of small businesses in New York City are still closed, like with San Fran. Does anyone know?
I’ve been avoiding the place like the plague. (Ha Ha)
What do you think will happen when the fires start up again? There seems to be a stumbling recovery in some sectors right now, but choking smoke and rolling blackouts look to be an ongoing trend.
This is from someone living in the current heatwave in BC, although it looks like it will begin to break for us this evening with a return of strong westerlies. (Around 99-102F for the last 4 days). I live on a decent size river and it has been so hot not one kayaker has been sighted for days. Tourists? staying indoors at home it looks like. I mention this because summer tourism to CA might become thing of the past going forward. The Pacific moderates the temp, and onshore breezes may keep the smoke inland, but last year’s pics are etched pretty deep.
The heat wave in the PNW adds a new twist to WFH. Lots of people who are stuck in un-airconditioned or poorly cooled houses and apartments are flooding back to the office today ( if the roads are any indication) for the commercial quality AC. My building is filled with young Intel employees and our Ac situation is not up to the 112 degree temps. I am looking out the window as I write this and people with name badges are jumping in their cars and heading out like it was morning rush hour in 1999.
Why are there people living in “un-air-conditioned” houses? They cost about $125.
Sorta ironic to me. I spent the unusually cold winter of 78-79 in Corvallis. People didn’t know how to drive on ice and snow. (Luckily my jump buddy was from Iowa when we went to Sheridan). Crashing closed bridges over the Columbia several times, and body shops had 3-5 weeks+ waiting lists. You could even fall on your ass walking to class if you didn’t pay 100% attention…pretty girls got a kick out of it.
I got to “see” my only total solar eclipse, too….around 9am but plenty low depressing dark clouds as usual. Birds went NUTS.
1) A SF small business owner insured his safe, protected properly with alarms, for $10M.
2) The landlord finally evicted the owner after a prolong non-payment.
3) A safe co crew opened the large Empty safe, detached the heavy
door, load them separately into the service elevator to the street, until the safe co truck picked them up.
4) After several years of law suits, the landlord will have another crack in his sinking building, if the landlord wasn’t careful, saving money.
5)He didn’t know what he couldn’t know that it was a professional setup.
And the City’s budget?
Even after the massive bailouts?
“So this is the economy of San Francisco. Fewer residents, fewer tourists, fewer jobs, fewer businesses, a still dead Financial District, lower rents, lower hotel room rates, near-empty BART trains, and lots of closed stores, but busy restaurants and lots of spending by the people that hung on.”
2banana,
California in general is incredibly dependent on the stock market and capital gains, which have been booming. And now California is awash in cash. Looks like San Francisco will end up with a surplus in the current fiscal year.
But yes, the budget is around $13 billion, and it keeps growing. On a per-capita basis, this has got to be the highest in the Universe.
Well, I have heard now is a great time to use the rainy day fund in CA to support a lot of these programs that has been put forth. How much of a hole in the budget do we think is going to be there as Gavin tries to stave off the recall by telling landlords they will be made whole.
Technically, this is federal money, so may be it isn’t part of the state budget, or at least not derived from the state income taxes.
Right now, Sacramento is floating in money. They’ve got so much extra money that they’re working hard trying to figure out how to spend it. They could replenish the Rainy Day fund or pay down debt, but that’s not going to happen.
I have three words for that, Wolf, High Speed Rail.
?
Meets all of the criteria, green, check, union jobs, check, shovel ready, check…. Ok, only kidding about the last three.
No one can ever build a high-speed rail system to connect San Francisco and LA because it would have to go through some very expensive neighborhoods at both ends, and they have totally blocked that. The only thing they can do is build it in the Central Valley, from Fresno to Bakersfield. And that’s what they’re doing. The rest cannot be done.
Heheh, you and I both know that… well, ok, I only know about it for the north end since no one in Palo Alto, Atherton, and Menlo Park would tolerate the noise. Don’t know anything about the south side.
But if they throw enough money and lawyers at the problem, eventually it can be done…
So, in the end, the green dreams of mass transit to connect large cities have been foiled once again by the rich, at the expense of the “working class.” That sounds like it could be a good political slogan if the politicians weren’t so indebted to those same expensive neighborhoods for donations.
The solution though is obvious, just move the working class out to Bakersfield and Fresno. Mass transit dream achieved.
“so many stores were vacant and forming a blight that the city imposed a vacancy tax to incentivize landlords to find tenants.”
Fascinating! I don’t what else to say.
I’ll bet the landlords were just thrilled about this…..as if it’s their fault.
Wouldn’t go to SF if you paid me.
Good to know :-]
Argyle, TX, where you are, is a great little place. Nice and warm in the summer. Been through there a couple of times by accident. If I were you, I wouldn’t leave either.
“Argyle, TX, where you are,”
I don’t know if Winder has shared hometown information here before. If not, I request Wolf to kindly not publish potentially PII.
Probably got it from the IP address.
Public forum, public IP. You want privacy get a VPN and sign in from Singapore from your safe space.
Michael,
Respectfully,
Perhaps you should stick to your area of expertise and not pretend to know the legalese of California privacy laws.
Hey nacho, show me where in the privacy laws Wolf is prohibited from making a generalized location statement. All I see are prohibitions about PRECISE location.
Currently California operates under the CCPA which addresses California residents rights when dealing with businesses that collect and sell their personal information. Thats not Wolfstreet.
And BTW, CPRA doesn’t go into effect until 2023. Even then it only addresses:
Businesses that satisfy one or more of these thresholds
annual gross revenues in excess of $25 million dollars (as adjusted for any increase in the Consumer Price Index in January of every odd-numbered year)
annually buys, receives, sells or shares the personal information of 50,000 or more consumers, households or devices
derives 50 percent or more of its annual revenues from selling consumers’ personal information
Go crawl back under your rock.
My bet is that Wolf keeps a note on each of his commenters and their comments. This allows him to speak with a level of understanding about his commenters. At least this is my blind understaning
“Go crawl back under your rock.”
What an attitude – I feel for your patients man.
Few minutes on Google made you a privacy expert now?
What’s your expert opinion on “CHAPTER 22. Internet Privacy Requirements [22575 – 22579]”?
Nacho Libre,
The IP address is in the public handshake that your internet service provider makes with every website you go to. The IP address belongs to the internet service provider (ISP) in a city and the fact that it is public makes the internet possible.
You can use publicly available sites to check IP addresses. Just Google: what is my IP address … and it will display your IP address.
If you use a VPN, the public IP address is not the one from your ISP, but one of the many IP addresses the VPN provider uses, which can be anywhere.
People should know this kind of technical stuff.
I do know that part. I also understand you get even more metadata – browser used, device used, os version number etc.
I am objecting to you publishing it without the user’s permission to poke fun at them.
Readers of this site don’t have access to your or any of other user’s information. You do and that should come with responsibility. It looks really bad if you start publishing someone’s information just because you disagreed with their assessment of your town.
Since your town and state is regulations heavy, I also encourage you to read up CA Internet Privacy Requirements and see what parts apply to your website business.
Let me get your fainting couch!
Fainting?
Node Centre, I am not 50 lbs overweight like you are.
Calling him overweight is a clear violation of HIPAA!!!1!
Not a Hippo violation. I am not privy to any inside information. Just repeating what he shared here publicly.
Nacho, I’m curious what you thought about the “PII” private part length debate on National TV…..offended?
Nacho Libre is correct here! thought the IP is not PII per se, (only Wolf knows they IP address of the users) and to assume people should know what a VPN is or use one, shows a lack of empathy for the non-technical inclined . Try to guess my city/town Wolf ;’)
Now I live in SF (for the past 5 years) and I beside the old folks, unmarried 45+, singles or couples with no children (which is the vast majority of the SF population). This city has so many problems, that these subset of the sf population can’t see or don’t care, because during the weekend everyone is out and about?
But anyways the problem with this city or maybe the whole “work-from-home” class is arrogance.
Ben,
Most everyone here is an anonymous poster using an anonymous or even fake email and screen name. Neither I nor anyone else here has any idea who these people are. You’re anonymous too. So I might know in what city some anonymous poster goes online (maybe in a coffee shop?). So what? I cannot connect that anonymous online persona with the real person behind it. I just disclosed where an anonymous internet persona with an alias as screen name went online. There are ZERO privacy issues involved here.
What I meant with people should know the technical stuff is not the VPN stuff, but that their IP address goes with them whenever they’re online.
“Daphne” and “Josephine” in Some Like It Hot –
“We wouldn’t be caught DEAD in Chicago!”
SF=Most beautiful city in the US. Wouldn’t live there any more. It’s best days were many decades ago. It was a lot of fun.
On the budget- it truly is amazing. I am not sure of the financial issues that have caused the state its great difficulties with the Average Joe (and lower income). The public school systems have been destroyed in the past 30 years. It’s an unbelievable story. (I have 3 former CA public school teachers in my family. When they taught, it was a fantastic educational experience).
189 billionaires?
SF WAS a really really GREAT place to visit, arriving:
Hitchhiking in for 4July holiday, ’66, from USN duty station,,, ”The coldest winter I ever spent was a summer in San Francisco.”
Actually spent the $$ for a cab to the airport to fly back to SoCal ASAP;;; cab cost more than the flight!
On the bus,’68-’82, $0.25, from Berzerkeley to the downtown SF bus terminal, and that included a transfer to the bus to Ocean Beach if wanted..
Usually walked from the terminal to the ocean on Sunday morning, right through Golden Gate Park,,, was full of wonder, far shore…did take the bus to the Great Highway to go to the Family Dog, nights.
Was, indeed, a wonderful city,,, my 2nd choice in the world, only to London, which I walked across from the west end to Finsbury Park one long night, after neglecting bus and UG closing time,,, and to be sure, that walk across London was equally fascinating as SF for some of us in the construction industry.
Most recently in and out of SFO, Bart and otherwise, not such a happy land, though plenty of competence at all levels…
Could not believe I could NOT buy an “Irish Coffee” at SFO because of some antiquated/anachronistic/BLUE law,,,???
And if that and similar not addressed in a really happy way, SF just fades back into the usual place of such similar provincial places, beautiful as they may be and have been…
wk
As a foreigner, my mental picture of SF will always be Bullit’s Mustang car chase of the 60’s.
I’m trying to imagine how Wolf’s parklets and sidewalk eating out would fit in to that. All the near misses with cable cars at junctions would be a safety plus, but it would be hard to get that big V8 revving at an average 31mph traffic speed.
Great to know what’s going on in other places.
My image of the city is Dirty Harry. No, not the child prince from Jolly old England, the cop in those five Clint Eastwood movies.
It doesnt fit with that image from the 60s. We are now living thru the last stages of an empire, right now what most people in all major cities want (or maybe even feel) is to eat at restaurants.
It sorta makes you feel wealthy, thats where the parklets and sidewalk eating fit into things. It was crazy for people to spend 30%+ of their salary in rent (this is not common) but people also spend 30%+ of their salary eating out (sad but truth)
Nearly everything in this post is happening here in the Swamp. Traffic jams are back and worse than ever because people have gotten use to driving verses taking public transportation. Crime is increasing, and income inequality has widened. The halves, the white collar WFH crowd, are doing great. Their equity in their RE has held up or gone up and they are trading up to bigger and better. Its La La land here. Even the tourists are starting to come back in droves.
Meanwhile, small businesses got crushed. Everywhere you see vacancy signs. At least 50% of the mom & pop business are gone for good. Out here in Maryland the same is true. Closures and bankruptcies everywhere.
Where will the unemployed go if 50% of mom & pop are gone.
What will happen when the delta variant strike next winter.
What will happen after they run out of Greek Letters? Roman Numerals like The Super Bowl?
Why hasn’t the city enacted a vacancy tax on those empty businesses? Or has it?
Why not levy an “idler’s tax” on the unemployed? How about a “sitting tax” on people in wheelchairs?
It will be something to behold when the imperial city gets sacked one day in the future, as in ancient historical times.
This almost happened last summer.
And the deed was finished on Jan 6th.
zr
Jan 6th was a peaceful demo by patriotic Americans. Turned into a police riot, sort of like Grant Park, Chicago in 1968
Went to my favorite Chinese take-out for the first tie in 1 1/2 year. Got tired of this tasteless English/Irish menu. By the way all the Chinese places here are take-out. No inside dining period. To top it off, you have to stay out on the sidewalk while waiting for your order. No place to sit down except to squat on the sidewalk or street or bring you own folding chair.
During Carter we had “gas lines”
So now we have “sidewalk lines”
I eat Chinese once a week. I call and pick it up 10 mins later, 15 if they’re busy. You walk in (they are behind plastic), pay and leave.
Are you really crying about getting Chinese take-out and connecting it somehow to Jimmy Carter?
Oh the awful troubles of THE WEST. “Boohoohoo…I had to squat down on the sidewalk OR sit in my FOLDING CHAIR….. while waiting for my Chinese food! Wahhhhhhhhh!! It’s not fair!”
You are the whiniest man alive. There are people starving to death on this planet. Some people have real problems. Death and destruction and warfare.
Try to keep your ‘troubles’ in perspective (but make sure you make at least one “Joe Biden is the new Jimmy Carter because a global pandemic happened and Chinese To-Go Food is slightly less convenient than before” rant every day, wouldn’t to miss that!).
Bitch slap fight! Go for it!
Wolf Street goes Jerry Springer. Next – Lesbian Vampire Hookers from Mars slap Trans Obese Body Modified Politicians from Middle Earth.
Trust me Wolf, it will sell.
nodecentrepublicansleft
Joe Biden has all the bad traits of Carter and none of the good. I’d take Carter any day. At least he was honest and had good intentions for the most part.
You aren’t a REAL Swamp Creature till you have a place in Hilton Head, trust me.
Good that came out of lockdowns ..
People have realised more money in their wallets ..
10% – 20% of people have stopped gambling as a recreation ..
No more going to the footy on the week end ..
Stuck at home, kids have had to get along ..
People have realised that not all food that is not prepared in their kitchen is JUNK FOOD & it is cost effective ..
Some times you just need a break from the usual routine to set you free to do other things .. we become obligated & repetitive so easily ..
Small business .. the guy who runs a small business that keeps him constantly broke & is killing him .. has been set free to live longer.
No one is using BART because of the large spike in crime based on the new political reality.
So they all went to cars. Thus the spike in traffic.
Good lordy. I just took the BART this morning — from Montgomery Station (Financial District) to Balboa Park and back, so twice. It was fine. It was clean. There were no issues anywhere. People were well-behaved. The only thing that is bad is the BART screech in the tunnels, some kind of technical issue with the rails and the wheels. But the new BART trains are here. I’m seeing them already though I haven’t been on one yet. I’ve never had a problem taking the BART, unlike you people who’ve never taken it.
Guessing flange resonance, like rubbing your finger round a wine glass. Very hard to cure. Sometimes they use oilers, but messy and big maint especially in tunnels.
Could easily be wrong!
Yes, I think you got it. BART did a study on it years ago and addressed some of it, and has a plan to address more of it, and I read a summary of it some time ago but now I cannot remember what exactly causes this harmonic vibration or how they’re planning to get rid of it. It gets very loud in some places.
The term BART screech is now a google-able term :-]
The metro here is working great. I’ve taken it many times during the pandemic. No crowds, people are polite. This talk about crime on the metro is a gross exaggeration. I would prefer to ride the metro over being in these traffic jams with all these maniac drivers any day.
San Francisco local paper said there were 35,000 city employees. Assuming that is accurate, I’m wondering, for a town with 875,000 residents, is that a high, average, or low percentage of city employees.
Well….Toronto has a population over three times the size and has around 35k city employees.
It would be a meaningless metric since some cities provide public utilities and others don’t and some do it by subcontracting with private companies or other municipalities or agencies etc.
In silly PDX, these parking space picnic benches are all full (and awful) by two pm with stimmy drinkers on any Tuesday. I feel a little too close to traffic to enjoy those “parklets.” The appeal of paying restuarant prices to sit on a picnic bench and order by phone during covid theater wearing a face diaper escapes me. Used to eat out every single day, for 16 years. I’m done eating out these days.
As a swimmer, the shutdown of all the pools has had the largest impact on me. It’s been 15 months since I had a good swim and I’m definitely feeling it. I was an open water swimmer in the Floriduh in my youth so I have no fear of the deep but there is no way I’m getting in that cold frickin Pacific water.
otis, you left out the part that in many of these roadside “picnic table” dining rooms that you have to go in and pick up your food when you order it on your phone because they are too short staffed to be able to bring it to your table. Plus you are easy prey to be “shaken down” by the panhandlers while at your table. And if you are eating at the wrong place and wrong time you might get verbally accosted (or worse) by the Antifa protestors roaming the downtown area looking for windows to break or statues to knock over.
“but there is no way I’m getting in that cold frickin Pacific water.”
Try it. You might like it! It’s addictive. It gives you the best high you’ve ever had. Just be careful and start slowly. Learn the signs of when it’s time to get out. Hypothermia can be deadly when you’re out in the open water. Best to try with a swim club where you can get the support you need when you first start out as “cold water swimmer.” They’ll tell you about currents and all the other stuff that you need to know.
Do you wear a wet suit? I remember everyone wearing one back in 1970 on my tour of the city just.
I used to when I started out on my own. Then one day I took it off and it was wonderful. Then I joined one of our two swim clubs here where no one uses a wetsuit. Never swam with wetsuit again.
The first thing you need to do is train your brain not to panic during the inevitable “cold shock” when you first get into the cold water (your chest locks up and you cannot breathe). After that, you’re good to go. Then the trick is to know when to get out. Everyone has their own limits. People with even a little insulation can stay in a lot longer than lean people like me.
Hard core! I always figured wetsuit….understand sauna now.
I did a fair amount of ab diving, but entry was always ragged. Learned to save a lot of pee to overcome the worst shock. After a while, though, you often get hot as hell and find a rock you can crawl onto and unzip.
Also remember the days when our dad’s used waders at the right place and an extra low tide.
Was told Game Wardens now watch with binocs to make sure everyone dives….no more just having enough Licenses for the group.
If Big Tech gets broken up that could derail the recovery.
Because monopolies are good for an economy?
Or is this satire?
There’s a long history of breaking up monopolies in this country. Did the country suffer afterwards? No. Lazy incumbents tend to just sit on their behinds, barely doing anything new, while raising prices for everyone else.
Big Tech used to innovate a lot more when they were SMALLER.
In 1984, the MaBell local telephone service was broken up into seven Baby Bells as part of the agreement. So there wouldn’t be a monopoly on Telephony companies. Well look at what happened. It all amalgamated back together. While I agree the MAN should be broken up I really don’t see that as fixing any problems.
Imagine if the then monopoly telephone company decided who would get a phone and what you could say on the phone based on your political viewpoints.
So why is it different today?
That’s because the regulatory regime took a turn for the worst once RR came into office, so they were able to put Humpty Dumpty back together.
What you are not getting is that mobile technology was lockup in the ATT umbrella. The company needed to be broken up to unleash the technology. Before the breakup, ATT and the Bell companies had no incentive to modernize, because the income was guaranteed with no competition.
If it wasn’t for the breakup, they would still be sitting on mobile phone technology. They also had video conference calling like zoom and texting too, in the 1960’s, and didn’t promote it mostly due to union pressures.
Actually, this for Pet:
SO glad you commenting , from experience, on Wolf’s wonderful forum,,, saves me a lot of typing, etc.
Thank you!
Petunia, when I was at ARCO in Los Angeles in 1981, we put video conferencing centers in 9 of our major operating locations worldwide. Zoom is nothing new except it is now PC based.
ITT
I left SF for the East bay 35 years ago and have always planned to move back when the kids are grown. I was going to return in the next year or so anyway but reading this has made my day! I keep thinking of the song we’d sing on our way home from road trips when I was a kid: San Francisco here I come, right back where I started from! The greatest things about The City never change: the weather, the hills, the views, GG park – so it’s nice to hear the crowds have thinned out a bit and the atmosphere is more relaxed than in recent years.
Looking at Craigslist, there is basically NOTHING for rent in Marin as smart people, especially with school age children, have now fled the city for greener pastures among the white clouds. They will never return.
Devon,
Good lordy, what BS. So I did a little research for you. Apartments.com lists 425 apartments for rent in Marin County (a small suburban county with only 285,000 folks, and most of them live in single-family houses. There is only a relative small stock of rental apartments in the county.
Why would post such blatant lies and ridiculous statements?
Tucker….is that you?!
Couple data points:
1) The former Marriott Courtyard on 2nd street – now the Clancy – appears to be packed. I’ve never seen so many people out front waiting for Uber/Lyft/taxis except during say, Dreamforce like conferences.
2) Rental cars are back. For a long time – there was an enormous shortage of rental cars in SF and SFO due to fleet reductions.
But this past Juneteenth weekend, the Hertz on Mason garage was completely full and prices were lower (albeit still very high).
Lastly – it looks like the big high rise dev on 1st – they’re breaking it down at least partially.
1) Crazy game Cro 3: 3 Spain, overtime.
2) La Liga on ESPN, from Aug, compete with EPL.
3) Great Thorgan Hazard anti parabola gave Belgium a victory.
4) Great bouncing parabola fooled a professional Spanish goalie.
5) The ball popup on the grass changing direction every contact, because of the spin.
6) The goalie try to stop it, but the ball rolled over his foot, because his foot became a ramp. And the ball cont straight to the net. It’s not a high school mistake!!
7) min 100 Spain 4:3 Cro.
Soccer aka futbol = yawn
:)
The real opium for the masses.
Similar to USA baseball; if ya don’t get the nuances, ya don’t get the game::
As a big fan of baseball since playing 2 player ”work up” age 7, then ”shagging” foul balls over the right field fence hit by Ted Williams ( after his service in Korea ‘) and his contemporaries at spring practice, state champ LL, , , and having explained the nuances, some very very subtle, etc., to more than a few folks of all the current generations, it’s not going to be an easy ”read” to understand ”futbol” for those who thing ”murrican football” is a sporting enterprise.
it’s actually the most popular sport in the world. and it called football is all other countries.
It’s also something to talk about at work. That’s why the sports highlights are at the end of TV shows….ya have to watch more commercials so you can act like you watched the game. Being a real hard core sports watching fan takes a LOT of time. Had a buddy at work who used to test for phonies by making up fake pitcher names. He had 7, yes 7!, Croix de Candlesticks.
NBay-was he the source of “…the beer that made Mel Famey walk us…” joke?
may we all find a better day.
Looks like enplanements suffered a mid-flight deplanement in early 2020.
8) BLM Olympics to shame US.
They are only hurting themselves and their future endorsement deals. If you think the NFL got a butt kicking, just wait.
Yeah, on a small scale, I have several friends who have been long time season ticket holders with the Texans football team. They all cancelled (sold back) their seasons tickets this year and going forward. Small point of course, but this stuff tends to spread.
Besides, our star quarterback has been “in the news” and being sued for inappropriate “things” he did at a dozen of so message parlors this past year. Quite role model for the youth around here. He is also asking to be traded but no known offers for his mega millions contract.
Professional sports in this country is gone to hell.
The NFL only got a “butt kicking” in the minds of the Fox “News” zombies. Meanwhile, in reality:
1) Super Bowl LIV was easily the top program of 2020, with 102 million viewers on February 2.
2) Seven of the top ten telecasts of the year came from the NFL, and 28 out of the top 100 of the year.
You’re only winning your ‘culture war’ in your mind.
The NFL is so popular, it took Sunday from God. It’s on from 10AM – 2AM on Sunday, Mon night, Thursday night and is spreading to Mexico and Europe. So yeah….real ‘butt kicking’ they took.
Of course the super bowl rocked. The ageless, mask less, buddy of the evil one was at center stage.
Crazy day : France out !
tomorrow, England out. Keep your John Terry jersey in the closet.
The economic carnage to come is pretty amazing. Over the past 4 months, the Treasury has not had to sell bonds, as they spent down the reserves. But that stops in another month or so.
So at the same time the Treasury starts to need to finance about $250-300 billion per month (the rough amount they have been drawing down from reserves), we will have unemployment expiring soon after, no more stimmie checks and no more PPP funds going out. Yes, Americans are still flush with money in their bank accounts, so there will still be some spending going on for the remainder of the year, but there are some areas where spending is not coming back – like business travel.
At the same time, we are looking at housing turning from a seller market where there are no listings, to a balanced market and then a buyer market, as higher interest rates will lead to higher monthly payments, and hence, to less people able to qualify for the high priced real estate.
This whole fiasco just looks like it is stacked up on top of itself and ready to implode at some point. My guess is the timing is based 100% on when the Treasury goes back to needing to finance the deficit. That will be the equivalent of turning off $250-300 billion of economic stimulus per month. It might take a month or two to suck the pent-up stimulus out of the economy.
So many If and When and In the future statements. I think the government did a fantastic job of creating a masquerade / illusion that everything was fine long enough for people to buy into the madness. Thus creating a bottom to the markets all around. They have certainly used their tools to put $$$ in pockets of everyday folks and a lot to the bankers and power dealers. But no mass riots and nobody was able to get anything like the 2008 Occupy Wall Street
Maybe some of those future items mentioned in your post will come to be. But for now the snow is still swirling in my snow globe
I flew to Wichita, KS 2 weeks ago for business. Went from Tampa to Dallas-Ft. Worth to Wichita.
Every single plane I was on was packed and I spoke to at least a dozen people, all traveling for business.
I’m a naysayer too, so I get it. But all of the doom and gloom that’s prophesied here….it has no meaning. Might as well study apes playing Yahtzee and pontificate about that. It would be about as meaningful.
The Future is Unknown.
People are tired of being cooped up and just want to be out. I made my husband take me out shopping this past weekend because I wanted to get out. Some stores had few customers, some were normal, and some had very long lines for the registers.
We each bought something we needed, so it wasn’t wasted time or money, but we hadn’t planned to go out or to spend money. I think there’s a lot of that going on right now. But once people blow their stash of cash, taking a trip or shopping, it’s back to the new boring normal.
I hope the Bay Area gets its act together. All the equity refugees are flooding Bend
I just read an article today on cbslocal about a survey that the SF Chamber Of Commerce conducted. It found that more than 40% of the people surveyed (registered voters) plan to move out of SF in the next few years. I wonder how accurate/relevant this is.
roddy6667,
Yes, that’s funny. They or other orgs produce these surveys every year. And every year, 37% or 40% or whatever of the respondents say they want to leave or will leave eventually.
And yet, the population kept growing every year. I keep telling them: Just do it. But no, they’re dilly-dallying around.
But last year was different. And quite a few people actually did it and left, and the population dropped by 1.7% — not 40%. This year, there might still have been some loss of population. But this mass-exodus that these surveys keep promising never arrives, and San Francisco has just gotten more congested every year (except 2020).
“Traffic congestion on the freeways is back .. phew !! “