Goods producing economy suffers globally. Services expected to keep it all taped together.
“There remained notable differences in performance between the manufacturing and services sectors. Whereas manufacturing production fell for a third successive month, service sector growth was sustained at a solid, albeit slower, rate” – so the IHS Markit Composite PMI this morning about the Eurozone.
And that is a global phenomenon that also is playing out in the US. In Germany, the contrast is particularly sharp: The manufacturing contraction has become steep, even as services are growing strongly.
The J.P.Morgan Global Composite PMI, also released this morning, which combined services and manufacturing for the major economies around the globe, picked up the theme:
The global service sector continued to outperform its manufacturing counterpart in April. This was despite output growth easing to a three-month low, with decelerations signaled across the business, consumer and financial services sub-industries.
Conditions in manufacturing remained lackluster, with production still rising at a near-stagnant pace. The consumer goods sub-sector was a bright spot, seeing growth accelerate to a three-month high. In contrast, output contracted in both the intermediate and investment goods industries.
And it added:
Subdued international trade flows weighed on global economic growth in April, with all-industry new export business falling for the fifth straight month. A further drop in manufacturing new export orders was only partially offset by a modest increase at service providers. Germany saw a marked decrease in foreign demand, China a modest decline, and the US mild growth.
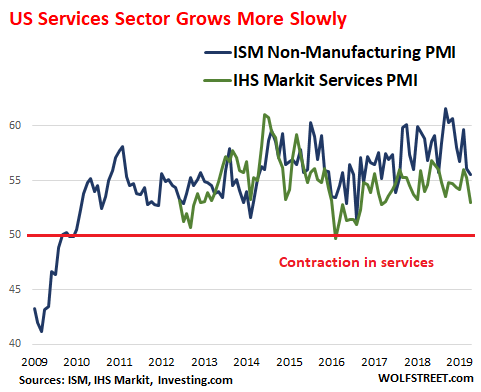
For the US services sector, this was confirmed last week by the Non-Manufacturing ISM Report and the IHS Markit US Services PMI. With both, a value above 50 indicates growth and a value below 50 indicates contraction in the services sector. The higher the value, the faster the growth.
The ISM Non-Manufacturing Index ticked down to 55.5 for the April reading, from 56.1 for March: still solid growth but below the red-hot growth spurts in September, October, and November 2018, when index levels went as high as 61.6 – not a very common sight, with index exceeding 60 in October 2017, and in July 2015.
Every sub-index was in growth mode, some more so than others (above 50 indicates growth): New orders backed off to 58.1 (from 59.0 in March); Business Activity/Production rose to 59.4 (from 57.4); New Export Orders – this is for services where the US as a trade surplus with the rest of the world — jumped to 57.0 (from 52.5) and Imports also jumped to 55.0 (from 51.5).
The IHS Markit US Services PMI also ticked down in April to 53.0. The report:
April data signaled a slower increase in business activity across the U.S. service sector. Output rose at the softest pace since March 2017 as new business growth also eased to a two-year low. Despite a further increase in backlogs of work, firms reined in their hiring, with the rate of job creation slowing to a two-year low.
Uncertainty and increased competition meanwhile pushed business expectations to the lowest for almost three years, while rates of input price and output charge inflation eased to 26- and 18-month lows, respectively.
The chart below shows both indices: the ISM Non-Manufacturing Index (blue line back to 2009) and the IMS Markit Services PMI (green line, back to 2012). Above the red line (above 50) indicates expansion in the services sector; below the red line indicates contraction (data via Investing.com):
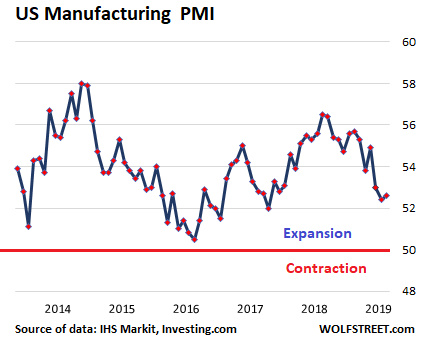
The US manufacturing PMI ticked up a tiny bit in April, and remains in slow-growth territory at 52.6 — and thus the cleanest dirty shirt among the largest economies. “Although faster than that seen in March, the latest upturn in production across the goods producing sector was among the softest seen in the last two years and below the series trend,” the report said:
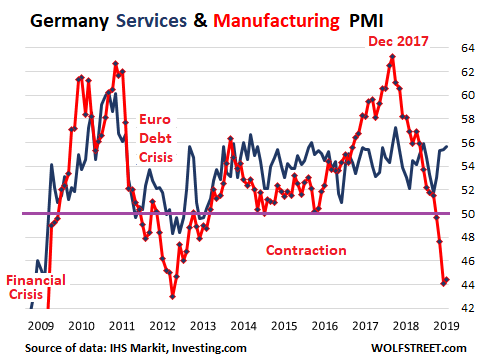
No country displays the split between manufacturing and services growth more harshly than Germany. The manufacturing PMI for Germany is in a steepest contraction since the worst moments of the euro debt crisis, with a value in April of 44.4 (below 50 = contraction). But the services PMI, released this morning, rose to 55.7, the fourth month in a row of increases, the highest level since September 2018, and above the long-run average of 53.3. IHS Market added:
Furthermore, the sustained upturn prompted firms to create jobs at the fastest rate since 2007. Wage pressures meanwhile underpinned a steep rise in service providers’ costs, which in turn contributed another sharp hike in average prices charged.
The chart below shows the divergence in Germany of the strong services PMI (blue line) and the plunging manufacturing PMI (red line):
The J.P.Morgan Global Composite PMI, tracking services and manufacturing around the globe, reported this morning that New Export Orders remained in contraction in April, and backlogs fell into contraction. The other sub-indices were expanding, but at slower rates, and “business optimism dipped to a near three-year low in April, with confidence easing at manufacturers and service providers alike.”
Enjoy reading WOLF STREET and want to support it? You can donate. I appreciate it immensely. Click on the mug to find out how:

![]()
One explanation (especially in relation to Germany) is that as the global economy slows it is felt the most quickly in the countries and economies outside the financialized core. Most strong manufacturing countries export a significant portion of their manufactured goods (especially Germany). So when formerly strong export markets such as Turkey, Argentina, Mexico, Brazil, etc. fall on hard times they buy fewer cars, tools, sensors, pumps and control systems from Germany ( or the US, etc.) But these core countries still have sound currencies, and strong markets so nobody is giving up haircuts, or cable tv or boat insurance just yet. But the service market can be fragile and when the manufacturing job losses start to stack up and people have to start making hard choices the barbers and yoga studios will feel the pain.
Wolf,
Thanks for the update.
One wonders how long services can carry the entire economy when manufacturing goes into contraction. Perhaps Germany will provide us with a test case?
Germany’s official GDP forecasts for 2019 have been shaved down from 2% a little over a year ago to very close to 0% now (but still positive by the slightest margin).
That says it all.
I guess that’s the consumption pattern of my Boomer parents. There’s nothing they really need to buy that manufactured; just food or goods that are part of health care services.
I’m a retired boomer. I’d guess 80% of my total expenses are for services. In addition to food & healthcare, I have monthly expenses for the following services (some geezers have more or different services, some have fewer):
o barber
o cable TV/phone/internet
o cell phone (amazing % of parents pay for kids)
o club dues
o DMV – auto registration (thinking of YOU, California)
o HOA/condo dues
o housekeeper
o insurance – auto
o insurance – home & liability
o insurance – LTD (Long Term Care ins)
o pest control
o pet grooming, medical, boarding
o pool services
o travel
o uninsured health care: medical co-pays, dental, eyes, Medicare part A (depending on income, it’s about $6k/yr)
o utilities – electricity & gas
o utilities – water, sewage, trash, other
o yard service
I’m unsure if the following qualify as goods, services or something else entirely:
o state & Fed income taxes
o restaurant meals
o home mortgage (I assume principle is “goods”, interest is “service”)
o real estate taxes
I guess my expenses are:
Food – groceries
Food – restaurant meals
Cell phone
Bike repairs/parts
Taxes
Clothing – just discovered MUJI T-Shirts great + cheaper than Target
Books.
Germany as a percent of economy does much more manufacturing. Services are lagging indicator. Stuff the pipe.
Dang Lawyers!
In other words, the service sector is “growing” because it’s billing more and taking a larger portion of the economy as it’s out falls (US life expectancy is falling 3 yrs in a rows as healthcare takes every larger fraction of the economy…financial services industry grows ever large as Super Ultra Dove Deluxe Fed don’t see no inflations and we all the value that gets us…debt enslaved students spend more on fake education for less actual service delivered).
Looks to me things are going exactly according to plan.
There is no more healthcare for most of us. Medicine prices are way, way, way up, and access to doctors at all is way down.
Healthcare is about 18% of GDP in the US. So if they’re selling that much healthcare, someone must be getting it
:-]
The top 10% are getting it. My boss just had “the equivalent of a small car” worth of money spend on his teeth. He injects insulin a few X a day, he takes a sleeping pill, has other pills – he and his wife start and end their days with handfuls of pills. Regular check-ups, occasional surgeries for iffy knees (due to overweight) etc. They’re getting a ton of healthcare. They’re very profitable.
Times are better than ever for the top 10%, for people like me, in the bottom say 30%, well, to me the old Soviet Union sounds like it was pretty danged good.
>US life expectancy is falling 3 yrs in a row
Opioid crisis, people dying in their 20’s and 30’s skew the numbers
>Opioid crisis, people dying in their 20’s and 30’s skew the number
they are still dead. suicides count, too.
“In other words, the service sector is “growing” because it’s billing more and taking a larger portion of the economy”
mirrored my thoughts exactly. almost all of the inflation in my life is due to health insurance and educational expenses. those are cartels with no real competition. most “things” can be price compared on the interweb and delivered to my door.
I’ve read that global semiconductor sales are down 13 per cent on last year (partially driven by crypto-scam collapse). Obviously now that “chips” are in everything, this would be some sort of indicator. We have reached peak CPU speed and slightly older hardware performs pretty much just as well as new stuff, so people are hanging onto their electronics for longer. This is despite what manufacturers are doing to cripple battery life and software compatibility. Since electronics would be a huge part of the modern consumption pattern, any fall there would reverberate. As manufacturing gets more efficient, there has to come a point where it completely meets all demand, thus satiating that demand (and nullifying it). Capitalism has worked extremely well at achieving this end. Now we need a new system post-rampant-consumptionism. And we need a new yardstick, since using GDP as a measure of “wonderfulness of life” is now just an antiquated and sick joke: “the rich get richer and the poor get brats” (and “gig” jobs and unaffordable housing). Money is only a tool and not a goal or a god. Seems to me some fellow said something similar a few thousand years ago.
I know many Youngers who ONLY have a large smartphone. Gone are the days of computer and smartphone since cloud apps work well on smartphone.
The worst part of checking GDP numbers is seeing them propped up by Government debt. It should be replaced with a system giving debt a higher risk metric.
The manufacturing sector has been in a long term downtrend.
32% of workers held manufacturing jobs in 1953, this has fallen to just 8.7% as of 2015.
Manufacturing’s share of nominal GDP was 28.1% in 1953 and has fallen to just 12% as of 2015.
These are good paying, solid jobs. Fabricators, welders, engineers, mechanics, carpenters, plumbers, heavy equipment operators, etc.
To think that the coffee barista, waitress, bartender, bank teller, shares broker, financial clerk, or banker, will step up into the breach and replace the loss of solid GDP, is to believe in a “fairy dust” economy.
They can learn how to code and become web developers and software engineers. Also jobs in AI and machine learning are going to be huge. Seriously why would anyone aspire to work in a bar or restaurant except of course if they are the owner
NickL: So what does one do when one was a software developer, but now is considered “too old” (over 40) to work in the industry? Become a barista? hmmm? IBM is “outplacing” all their “old” staff by stealth: search it on the interwebs (there are class actions being prepared). This is normal corporate practice now. The young ones are used and abused as interns, then replaced with the next stary-eyed batch. Also search about all the strife in the (so called) “booming” games industry (long periods of “crunching” etc). The actual long term “coding” jobs have long since been shipped off to the incompetents in india and those actually making things in china. Technology is moving so fast that by the time they graduate, all their overpriced tuition will be out of date. Plus, not everyone has the autistic attributes needed for such a job, so your comment reveals a rather simplistic world view. There NEEDS to be jobs for all types of people (even “old” ones), not just STEM types. Otherwise you will destabilize society. If industry can’t do it (as they have proven), then government needs to step in. Victim blaming brings us no closer to any sort of remedy. At least the current President is actually doing something rather than just sprouting populist platitudes of the previous laissez-faire policies which caused the problem. He was/is “one of them” and is no patsy when it comes to deceptive corporate shenanigans. Actual jobs need to come back to every country, not just America.
No one’s going to hire a 56 or 57 year old novice programmer.
The economy is already to the point where if you are in your 50’s and lose your job, you may never find meaningful work again.
A 74 year old guy stopped by my store to sell some silver to help out with the end of the month shortfall in income vs. expenses. He has been looking for a job but no one wants to hire a 74 year old. The state took away his CDL last time he renewed his license (my guess is that was a good thing) so he cannot drive a commercial vehicle. I assume he will not be a gig as a Lift or Uber driver.
A woman in her 70’s also talked about the same problem, can’t get a job, but does not have enough income to live on.
Older workers are becoming obsolete.
When I read patronising comments about people who work in retail, bars, etc, (”You’re just schmucks, re-train!’) I cherish the thought that the commenter might one day end up in just that kind of job, which to the majority of people is their only option – and a very respectable one at that.
Our economies have to be able to provide decent basic employment for the majority, with fair pay and working conditions (not Amazon warehouse level): this has been lost sight of by the conceited and privileged.
As (‘good’ )King Henry IV of France said 400 years ago to his ministers: ‘If you screw my people, you’re screwing me!’
Personally, I’d rather work in a good small restaurant, with a decent boss, than for a corporation that shows no loyalty to its staff whatever scope it seems to offer to ambition.
Thank you! Retail need not be frowned upon. I work on that side of the counter and amazed at how some folks actually look down upon me. I’m in my late 60s. It is respectable, and does serve a valuable purpose. I work for a small private owned business.
NickL – Not sure if there is a note of sarcasm there. It is fine for the airheads to say the traditional jobs will be replaced by coders etc. Even if this were true on an average or 30,000 foot view, but what happens to the actual people involved? The UK gov and others are breathlessly pushing for driverless vehicles, even subsidizing development. What are the 4 million UK truck and delivery drivers going to do, become coders? I think not. They will be wards of the state simply to improve corporate profits, what responsible gov would encourage such a thing?
@Ian –
Automation increases the goods produced per unit labor – it’s hard to argue against that. Today’s truck drivers will be displaced and it is the role of society and politicians to manage that transition, not to create or maintain make-work jobs.
I believe the real dilemma is how one goes about structuring a society where an increasing fraction of the society cannot add value due to age or cognitive ability. I suppose soon enough (100-200 years?) humanity will be bio-engineered, if it exists at all, and the question will be moot.
“I believe the real dilemma is how one goes about structuring a society where an increasing fraction of the society cannot add value due to age or cognitive ability.”
jordan peterson brings up this question in his lectures but he is not allowed to speak in polite society. he claims that the data shows that fully 10% of the population isn’t smart enough to be gainfully employed. i’m not a libertarian because i believe that the government does have the responsibility of taking care of it’s more vulnerable people. but, as margaret thatcher pointed out, “the problem with socialism is that you eventually run out of other people’s money.”
The entire point of coding is to eliminate jobs. Code is used to automate jobs so fewer people are required for each task a code gets made for. You can’t replace pay cheques by rendering your own job mute.
Bank tellers are going away with automated phone services and ATMs, taxi’s and ubers will be replaced with AI, same goes for long haul truckers. Brick and Mortar has been gutted by coding, layman just like to point at Amazon but all of e-commerce has been automating the stores away.
Activision Blizzard fired 800 workers, most with plenty of experience. Only to post their jobs looking for younger and cheaper talent.
At least baristas and waiters offer real services. The deadwood weighing the real economy down are the middle managers who reinvent power points all day and and rent seekers – those who flip houses, IP trolls or those who traffic in dubious and exotic financial instruments.
Alternate statistical view (or, the fairy dust may not be where you think it is):
o In USA, mfg employment was 32% of a MUCH smaller 1947 labor market (19M jobs); in 2015 it’s currently 8.7% (12M jobs) – over 70 years, USA mfg job count has shrunk 35% from 19M to 12M.
o During 1960-2015, EVERY top-20 advanced economy had declines in mfg jobs as % of total jobs – USA % losses were about in the middle of the pack. Essentially mfg jobs grew and/or migrated to Asia & India.
source for above : https://ftalphaville.ft.com/2018/04/17/1523941200000/The-decline-in-manufacturing–charted/
o In USA, 4.6% of workforce had college degrees; in 2017, 33.4% have degrees (https://thehill.com/homenews/state-watch/326995-census-more-americans-have-college-degrees-than-ever-before)
Some mfg jobs have indeed gone due to productivity & off-shoring. Undoubtedly some degreed people stayed in mfg, but one might logically question the economic benefit (ie: paychecks) to all that college degreed labor presumably trying to move into other equal-or-higher paying non-mfg jobs.
Yea, I know – a college education is not supposed to be job training; however, 67% of 2016 graduates had student debt, averaging $40,000. Someone has to feed the bulldog.
clarification:
in 1946 USA 4.6% of workforce had college degrees; in 2017 USA has 33.4% with degrees
Well, if you listen to the talking heads, the service economy is where things are at, it’s what Americans are good at, and the opportunities are huge, blah blah blah.
Those good old solid jobs you mentioned has long ago been offshored. We are now all about the information economy, except I think somewhere people are starting to realize how that information economy might be useless without things like hardware (thinking of fiber optics, and 5G, and all that) which we no longer make here. Because it was considered inefficient to manufacture here. Well, now we reap what we’ve sown.
I remember this lovely refrain from the tech executive of the late 90s and early 00s when they were asked how they could overcome China who copied everything. Their answer was equal part ignorance and arrogance: “We’ll innovate faster, and expect always to be a generation or two ahead.”
Arrogance as in, those Chinese guys can’t innovate on their own. All they can do is copy. Ignorance as in, whom are we going to leverage to innovate faster, we’ve offshored the infrastructure and the capacity for it.
Heh, you know what I keep hearing on the radio is how manufacturing jobs wasn’t just offshored, it was automated away. Yeah, you wanna know what’s going to get automated away even faster? Service jobs.
Wait until the day your Uber/Lyft/whatever picks you up without a driver. The ride will be cheap, but only because those service employees got put out of work.
{end rant}
“Wait until the day your Uber/Lyft/whatever picks you up without a driver. The ride will be cheap, but only because those service employees got put out of work.”
_____
Overheard circa 1890 somewhere….
Oh my god!! If these new fangled automobiles take off, what will happen to all the people involved in taking care of horses and buggies? Our economy will be ruined!!!!
well, logically, all those service workers who have no jobs will just pick up programming and become experts at AI, I heard that they pay really well.
Or better yet, the hamster wheel that is used to charge those electric cars still need something to run in them, hamsters are too expensive, can we use humans?
And god help us if we get involved in a WW3…how will we build the needed arms?
Services don’t behave like manufactured goods when a recession does come. While manufactured goods can build up a backlog or deferred purchase, services don’t behave the same way. Just because I can not afford to eat at a restaurant this week, doesn’t mean I will make that back in a couple of weeks. Once a service recession starts it will be hard to turn around.
Look at the monthly job numbers: Every month pretty much 30,000 in health care and 20-30,000 in bars and restaurants. Yup a great foundation for future prosperity. All that is left is drinks at a bar, some lousy unhealthy food, and the medical care to try and fix the resulting mess.
Those eatery parking lots still look full– of nice SUV’s and long pick-up trucks. Fat people walking in and out. Mexicans are the only ones willing to work most physical jobs, I think they understand the value of an earned dollar more than most. Yeah, great foundation going on, what could go wrong?
Wall Street’s America second policies from 1970 to 2016 created the great bartender wave.
Being a bartender sure didn’t help anyone achieve the American Dream!
Oh, AOC just proved me wrong!
yeah, but were you as telegenic and of the right media requirements/narrative to have been able to fill in the AOC spot? You know, there are only 435 of those seats, I mean, you have to have the perfect mix of idealism, ignorance, and been of the “oppressed member of society,” and just photogenic enough (meaning, you can’t be Gisele, but you can’t be Urkel either) to fit in. It isn’t that easy.
But don’t worry, this won’t last forever, like old Syndrome said: “when everybody is an AOC, nobody is an AOC.” Ok, he didn’t say AOC, and the wording is a little off, but you get the idea.
Since unadjusted service sector inflation was at approximately 2.9% in 2018, how much of the PMI 52 is inflationary?
Very little or none because PMIs are not measured in currency.
Old Jew to young Jew in 1920’s Germany.
“we will not make any money sitting here selling each other haircuts.”
Old insurance salesman to undergraduate in 1970’s California.
“You technology and management people keep going the way you are. And one day. Americans will be selling each other insurance. wWhilst the peopel in Asia. Will be making all the money.”
1930’s Northern English Robber Baron.
Where there’s Muck (S^%t) there’s Brass (Money).
Scientific explanation of “work” involves the “Expending of Energy”.
Most modern Americans dont want to do any real “Work” or pay a “reasonable standard of living rate” for anybody else top do it for them.
Hence Japans urgency in developing AI and robots, to service their aging and shrinking population. as they understand their are to many people in Japan particularly poor ones. And the answer is not to import more poor ones,.
The global population has more than tripled since WW II. Those that do not see this as a huge problem, are part of the huge problem.
Or more bluntly.
When an Economic and Social System, based on ever increasing growth, fueled by credit and ever expanding population, meets a Finite Environmental space, containing Finite Resources. Both will Catastrophically fail.
Non-Japanese people do not do Japanese culture well. In the US, in our barbarian culture, we can bring in Filipinos and Mexicans and so on, and it works out great because frankly their cultures are nicer than ours. But doing Japanese culture really pretty much requires growing up Japanese.
I went to a matsuri (festival) in San Jose Japantown yesterday and brought my shakuhachi, and played it while my fellow “dress up” guys discussed things and an old Japanese guy came up and got in my face and made very sure that I understood that he loved to hear the shakuhachi, that I should keep working on it, that it’s a good, lovely thing.
Because it’s a hard instrument. It’s almost like training for a sport as much as an instrument; the kind of work Americans are conditioned to think of as a bad thing to do. But here I was, doing it.
I consider this old guy’s praise the equivalent of all the praise I’ve gotten as a busker, combined. Those old Japanese guys don’t fool around. It takes a lot to impress them.
But the thing is, Japanese culture is pretty advanced. They can’t just import any old people from anywhere and have it work, not even Americans or Europeans. Hence, the effort to see if they can get by with robots. Also, the line between human, animal, object… are more blurred in Japanese culture. So robots are not necessarily “the other” the way they are with us. I compare that with how, in “Western” culture, dragons are bad guys and in Asian culture, they’re good guys. As a kid who grew up with the book “Waldo The Jumping Dragon” I side with the Asian view.
Alex in San Jose:…….
“shakuhachi”
As an old clarinet player I paused and clicked on the instrument you indicated and was delighted with the absolutely haunting tones I listened to; which then led me to “dueling guitars”….and other calming effects to offset the disappointment I have with humanity today. Thx for the distraction!!
“But doing Japanese culture really pretty much requires growing up Japanese.”
Accurate assessment.
I don’t even want to think of those implications. Time to batten done the hatches and strengthen family and friendships.
And live 40 Meters above current king tide contours. With an allowance for erosion.
When Florida goes under peopel think insurance will pay.
Forecast.
Property insurers will all be bankrupt or protected from rising sea-level related claims by laws, before then.
Yea; give us a wake-up call when this REALLY happens.
You’ve just joined a long line of other “incorrect future-seers”, including Robert Malthus, who wrote the book on it in 1798 (roughly, Napoleon’s era). Luddites did the heavy lifting of being wrong in the 19th century; the Club of Rome (early 1980s) continued the “incorrect future-seeing” in the 1980s.
The forecasting problem with Malthus, Luddites and Club of Rome (and others in the apocalyptic crowd) is a tendency to straight-line current trends. It turns out, human civilization never movs in straight lines. Barriers to survival do, indeed, exist, but when encountered, human ingenuity generally finds creative ways around it.
No reason to suspect this will not happen in the future. Example: poorer people want more kids to help with subsistence farming and assist them in old-age; lifting people out of abject poverty is generally followed by declining birth rates. China has lifted about 400-500 million people out of abject poverty over the last 40 years, and it’s reasonable to expect their birth rates to drop.
According to the UN, Chinese population is expected to grow from 1.31B in 2005 to 1.46B in 2030, and then decline to 1.41 billion in 2050. (https://www.researchgate.net/figure/Trends-of-Chinas-population-growth-1950-2050-UN-2007-30-According-to-the-2006_fig3_259267076).
Tell me how you intend to prevent average sea levels rising somewhere between 6 and 30 meters in the next 80 years believe, it IS happening.
Land ice is leaving Antarctica and Greenland in ever increasing volumes far greater than even the worst scenarios envisaged.
When the entire belt from Louisiana to Minnesota goes under salt water, which it will after Florida. As it was 60 million years ago
Perhaps stupid Americans will finally see the light.
ANYBODY WHO CAN NOT ADMIT THERE IS A SERIOUS PROBLEM, IS PART OF IT.
What jobs would you rather have in America?
a. $200K engineer “service” jobs at Google or Apple or Amazon
b. $10/hr jobs making “stuff” that can be done for $10/day in the 3rd World
I know which one I want.
That comment gets four stars for silliness. Not everyone can be an engineer. Nor can an economy survive if everyone does the same thing.
Bit like the comment that says exploiting Asia is cheaper than making local.
which it is, until you damage the majority of the local consumer base, to the point where it can not afford to buy from Asia or pay local rent rates.
America is swiftly approaching that point.
Parts of California have already passed it. Hence the Homeless issues..
i wonder what percentage of american manufacturing jobs are in armaments? would boeing be such a powerhouse in commercial jets, if it didn’t have all those military contracts keeping the lights on when the commercial business slows down? the elephant in the room is america’s war machine.
safe as milk
10% (https://www.clearedconnections.com/security-clearance-news/security-clearance/defense-jobs-make-up-10-percent-of-u-s-manufacturing-demand.htm). FYI: start to finish, search & cut & paste took 30 seconds.
For me, comments are more credible if actual facts are cited.
Sadly, you only pay attention to the facts, that suit your agenda.
When we quit taxing jobs and start taxing polution, petroleum, plastic, pesticides, and poison, then we will have more jobs and less polution, petroleum, plastic, pesticides, and poison.
Amen.
Except that would be considered taxing consumption, which is considered regressive.
“Merely ‘externalities'”….pffffttttttttt!!
To borrow from a certain trends forecaster:
The business of China is business, the business of the USA is war
The service sector in CA is huge, everyone hires hispanic help, and it’s basically a cash economy. I have a relative who should be in assisted living, she needs to call the paramedics twice a month to pick her up. Won’t give up here house.
If we counted all the people who worked for subnormal, or no wages, volunteers, family caregivers, neighbors,etc, and gave them minimum wage, this economy would be huge. Below the 99% is another group just as large, and even more disadvantaged by the system.
it’s always been about labor..
and it’s always somebody else’s money,
did you think Maggie was spending her own.
The huge cut in corporate tax rates in the U.S. is killing investment in Germany. After tax returns on a new manufacturing plant in the U.S. leapt ahead last year, and the flows in direct investment reflect it. Inflows into Europe fell 20%, with the U.K.’s down 34% and Germany’s down 67%.
that’s how you spell chadenfreude.
er… schadenfreude
The US’s new corporate tax rates will indeed have a significant impact on domestic vs foreign capital investment decisions:
Trump’s tax cut reduced corporate tax rates from 36% (2nd highest in developed world) to 21% (heavily capital-intensive industry tends to pay a somewhat lower effective rate due to heavy depreciation/amortization);
German corporate tax rates are (and have been) about 22%.
My guess is manufacturing is the leading indicator in this instance.