The gloomy scenario the “smart money” is betting on.
US Treasuries set new records on Friday: The 10-year note rose to a new high, with the yield dropping to a new low of 1.366%. The 30-year Treasury bond also hit a new high, with the yield dropping to 2.11%, a record low.
If 2.11% sounds like a miserably low return for tying up your money for three decades of hell and high water, it’s practically bond nirvana for whatever else is out there.
The German government, paragon of fiscal rectitude at the moment, one of the few AAA-rated governments left on earth, is able to charge investors for lending it money: the 10-year yield ended the week at a negative -0.187%; the 30-year yield is still positive at 0.35%, but creeping closer to zero.
In Japan, it’s even worse. Fiscally, Japan is the opposite of Germany. It has a lowly A+ credit rating, a gross national debt that has ballooned to 250% of GDP, by far the worst in the developed world, and mega-deficits year after year. Yet its lost-cause debt sports a 10-year yield of negative -0.288%. Even the 30-year bond is dabbling with zero.
Swiss government bonds are the negative-yield-absurdity trailblazers: the 10-year yield, at -0.60%, is the most negative 10-year yield in the world. Even the 30-year yield is negative.
Financial repression, pure and simple.
At the end of May, the total amount of government debt with negative yields had reached $10.4 trillion. By June 27, it had jumped to $11.7 trillion, according to Fitch Ratings. Since then, even more debt has skidded into negative-yield absurdity, now exceeding $12 trillion, and moving inexorably higher.
“Merrill Lynch now says 29% of the global fixed income market is sporting negative rates, up from 24% pre-Brexit,” explained Christine Hughes, Chief Investment Strategist at OtterWood Capital, in her newsletter. It’s “a continued march south in global yields courtesy of the relentless demand for bonds”:
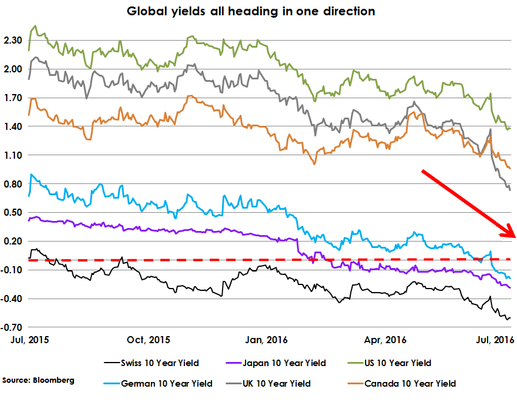
“It seems that the lower rates go, the more frenzied the demand,” Hughes wrote. And this is how far out by country the negative-yield absurdity reaches (chart via OtterWood Capital):
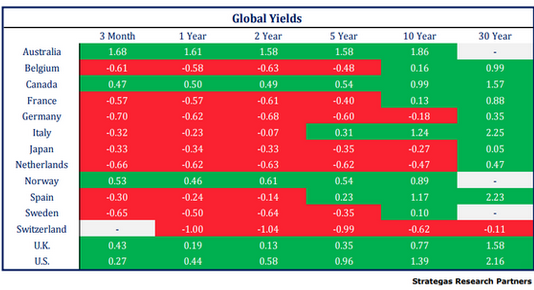
So over $12 trillion in investor money is stuck in negative-yield absurdity – an amazing feat in central banking, to convince so many investors, particularly the “smart money,” that this is somehow good for them, that paying money for the privilege of lending money to the government, no matter how decrepit its fiscal situation, even to Japan, is the hot thing to do.
But many big institutional investors have to buy government bonds, such as insurance companies and pensions fund, no matter what the yield. So there will always be a forced buyer for these instruments.
And investors that got in early made a killing on government bonds with long maturities, while some yield chasers going after the riskiest stuff got their heads handed to them (though some of them made a killing too).
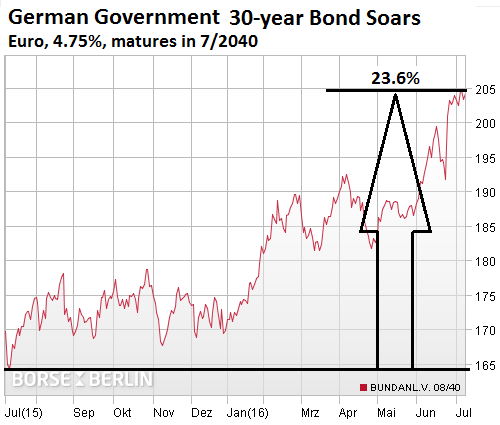
For example, the 4.75% German government bond that matures in July 2040, traded at 203.93 cents on the euro on Friday. It has more than doubled in value since it was issued in 2008. And this is what it has done, thanks to Draghi’s negative-yield absurdity, over the past 12 months. It has soared 23.6% from 165 cents on the euro to 204:
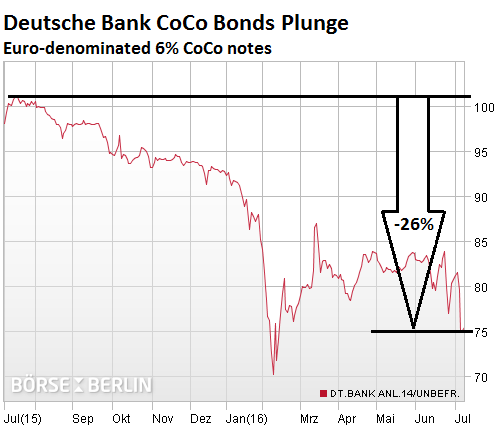
But yield chasers, those that take dizzying risks to make more money than anyone else, well, many did, but those that plowed into Deutsche Bank’s misbegotten contingent convertible bonds that have a coupon of 6% and that never mature, and that can be bailed in if bank capital falls below certain thresholds [read the sordid story… I’m in Awe at How Fast Deutsche Bank is Coming Unglued], well these courageous souls have lost their shirts. These 6% euro-denominated CoCo bonds have plunged 26% over the past 12 months, from 102 cents on the euro to 75:
So taking risks doesn’t always pay in this environment where central-bank NIRP-and-QE engineering teams have turned even the crummiest government bonds into a top-performing asset class.
Investors are now chasing other government bonds, such as US Treasuries, whose yields haven’t fallen to zero yet, so that they too can ride them into negative yield absurdity and profit from what must be one of the greatest scams in the history of mankind.
And then there’s fear. Investors are fleeing into the safest, most liquid assets they can find and for which there will always be an eager buyer, if push comes to shove: the central bank.
It’s the fear of global shock waves that don’t seem to end: slowing demand, consequences of Brexit, a hard landing of China or the implosion of its credit bubble, a collapse or spike in oil prices, a mess in Brazil, a banking crisis in Europe….
The fear of losing their shirts on CoCo bonds, junk bonds, or stocks. The mortal fear that central banks have already lost control over equity markets and other asset classes, combined with the knowledge that they will never lose control over their government bond markets. They can even dry them up, as the Bank of Japan has done, to where there is no more market and no more bond sell-offs.
Then there’s the notion that interest rates can never rise again. Even small increases would cause over-indebted companies, consumers, and governments (those that can’t print their own money, such as state and local governments) to go bankrupt simultaneously. In this theory, however unproven it may be, rates can only fall deeper into the negative to keep this house of cards from collapsing. And thus, government bond prices can only rise. That’s the gloomy scenario the “smart money” is betting on.
And in Europe, the banking crisis the smart money has been afraid of is coming into bloom. Read… I’m in Awe at How Fast Deutsche Bank is Coming Unglued
Enjoy reading WOLF STREET and want to support it? You can donate. I appreciate it immensely. Click on the mug to find out how:

![]()
It appears we are now in the end game of national/global economies based on continually expanding debt without limit, having already gone through the looking glass with negative interest rate bonds.
It may well be that the BoE will be the first central bank to be forced to acknowledge that the Emperor is in fact stark naked, and has been for decades.
It is to be hoped that somewhere in the maze of the UK government, contingency plans are being made in case Sterling and Sterling based assets implode to maintain essential services and supplies. While it will be very unpleasant, the country that withstood the blitz, and fought alone against invasion in the early months of WW2 with the support of their people, will survive the destruction of vast amounts of virtual/imaginary wealth.
It will be critical to stress to the people that what has “disappeared” was never real in the first place, and that the true wealth of the nation, such as a loyal and patriotic population, skilled and highly trained/educated workforce, physical plants/machines/products, sales/distribution channels, highly developed infrastructure, and export markets still exist, and only need to be intelligently employed.
We let too many academics and charlatans, got involved in politics and economies. The whole society lacks of practicality.
From what I understand, bond is used to be regarded as steady long term investment. Big institutions puts most of their assets into bonds for gradual organic growth. Now everyone is chasing it for short term gain like hot potato.
I agree, the traders who can do short term trading on bonds will make profit and long term bond holders like the general public that are stuck in the game will take the hit.
Joe, you said, “long term bond holders like the general public that are stuck in the game will take the hit.”
Exactly right! You can’t make money with these long-term bonds unless you sell them many years before their maturity date. As they get closer to maturity date, the value moves toward face value, and in the end, when they’re redeemed, all you get is face value. If you bought the bond with a zero or negative yield, you lost money on it, not even counting the effect of inflation, which eats into the purchasing power of that face value.
Is it possible that a negative bond from a place such as Switzerland is actually a form of ersatz currency trading? You’ll lose a bit of money on the bond, but you’re betting that the Swiss franc will accumulate relative to other currencies.
That wouldn’t explain buying bonds denominated in Euros, though . . .
For those with large amounts of money the word is TINA- There is no alternative- What are you to do with $100 million? Keep it on deposit with a bank and have it get ‘bailed in’ should the bank fail? Hope money market funds don’t ‘break the buck’? Keep it as cash in a vault and hope there will still be a Euro in 10 years or that governments don’t pull a North Korea and call in old currency and issue ‘new won’?
Since governments will pay off their bonds in some fashion the cost of zero or even negative interest rates is lower than the risk of outright default, confiscation or loss of liquidity is lower with sovereign bonds than other ‘investments’.
One would think all the money now would rest in certain commodities. If, as we see both governments and corporations go bankrupt (squishing consumers in the middle), then it would make sense to invest in raw materials as gold only goes up during depressions. Also water. Energy companies maybe. Nothing risky, like say rare minerals, though something that can be kept as currency if government structures disintigrate. That would be the most stable option as resources are the most universal currency always keeping with inflation
Realize the UK only survived WWII due to generous food, oil, and supply shipments from Canada and the US. Postwar, the U.K. Was also saved from absolute ruin by generous loans from the US, which were only fully paid back about a decade ago. The US now has the largest reserves of energy, higher than Russia or Saudi. Looks like another American ( or make that North American century), while the UK threatens to retreat into isolationism.
With that said, can’t go wrong with buckets of USD, seems like the only game in town.
İf you cant go wrong with dollars than why has the turkish lira strengthened from 3.07 to the dollar 9 months ago to 2.89 today not to mention the 10% interest rate paid on lira accounts İve stayed in the dollar and sorry that İve done that Nicko According to Peter Schiff the dollar is toxic and gold and silver are the answer
I actually live in Egypt at the moment, interest rates are running near 13%, inflation well over 10%, they’re expecting the currency to depreciate another 10% in the coming months, the local stock market is on a tear, local banks are giving 5% interest on dollar accounts. ….of course, there is a growing cash shortage, capital controls…much risk.
You have created some powerful imagery, but central bankers are not in the habit of pointing out the king has no clothes (“It may well be that the BoE will be the first central bank to be forced to acknowledge that the Emperor is in fact stark naked, and has been for decades.) A long as they can expand the debt, the king still has clothes, just more and more threadbare, and this goes in spades for the working man. The competitive national currency devaluations- always portrayed in the WSJ, the FT, the MSM as “spurring export growth” amount to diluting the children’s milk, and food prices are already fearful. It will be interesting, with a woman ‘s sensibilities to domestic issues, what course Prime Minister May will take.
RE: … but central bankers are not in the habit of pointing out the king has no clothes …
—–
Indeed they are not, and it is likely to required many and diverse sundry blows about their head and body before they will admit that they knew all along the Emperor was naked as a jaybird. After all their jobs depended on seeing his exquisite raiment…
While some sort of socioeconomic inflection point or “change of state” does appear imminent, most unfortunately this does not appear to be limited to a few poorly run and under-capitalized TBTF banks. Rather we seem to have “gone through the looking glass” with the central bank imposition of negative interest rates, and are now in the endgame of a global fantasy economy, supported only by ever increasing debt in a finite world. It was a good run while it lasted, but after 3 generations we appear to have reached the limit.
While the collapse of the virtual, debt based, economy will be traumatic, it need not be the end of civilization as we know it as long as the majority of people realize that the wealth/assets that vanished were never real in the first place, and that the real assets of the country such as a loyal and patriotic majority, a highly skilled and educated workforce, industrial and manufacturing facilities, highly developed infrastructure, abundant natural resources, adequate domestic food production, etc. remain, and only require intelligent and rational utilization to maintain an adequate standard of living for everyone while corrective, and hopefully preventative, measures are taken.
This fantastic honorable economy of your imagination will never ever see reality as the locus crux of CB profligate debt creation remains unfettered and proceeds unabated. IMO the plan is to bankrupt us all with debt and currency devaluations.
RE: … IMO the plan is to bankrupt us all with debt and currency devaluations.
—–
I seriously doubt that the current elite “plan” to topple the current socioeconomic house of cards any more than the French, Russian, and Chinese (and indeed the Roman) elites “planned” to topple theirs.
It appears the common thread is an increasingly rapid flight from reality by the elite (or more exactly reality rapidly departing from the “static” elite), with increasing reliance on a series of progressively ineffective stop-gap palliative measures to maintain >their< status quo in a rapidly changing environment (including increasing repression) rather than implementing proactive corrective actions.
What these proactive corrective measures might be no one knows, but what is clear that “more of the same, only better” is no longer a viable option.
Motives can be debated but the facts speak clearly: untold trillions have been pillaged from the future and funnelled to the elite. Then comes the inevitable collapse. If it weren’t for the overt market manipulation, PPT interventions and clarion calls for world government by the elite cabal I could be inclined to alter my opinion. But under the circumstances I won’t.
It’s not entirely unrealistic to expect a community based economy in smaller scales. If you seen any of the business models which sprung up in Greece after their collapse then you’ll know it’s possible. With the sharing economy moving into full swing and bartering economies like Simbii coming out, it might be possible to change to an economic foundation of knowledge vs our current bourgeois delusions to sustain some recovery to sanity. It will be very different from anything we can picture now however
Canadian bonds still positive i believe. We havent hit zero yet. Wolf i say if all this is the case then not should as near zero as possible. If rate never go up. Charge a fee on mortgage with zero percent. Love to see how high the housing market Will reach on that. personally we r out of a lot of options. We are all in this together make the best of a not so good situation. Make as much as u can before it implodes. U know the central banks have invested backs. Ride the wave and do your best to avoid the crash.
Canada is one of the few developed nations left with a AAA RATING.
I confess I’ve made a nice bundle over the past few years selling bonds.
I remember the bank manager questioning my sanity when I put an order for JGB. I told him it was a purely speculative endeavor. I had no interest in yields and was betting on the Bank of Japan’s kamikaze policy. It paid off, and nicely so.
I’ve sold off most of what I held and right now I have no intention of buying. Yes, prices may still and probably will go higher but they are too high for my liking right now. Gains are still there to be had, but the big profits are gone. Call me old fashioned, but I like to buy low and sell high, not buy high and hope to sell higher. ;-)
In a way the sovereign/investment grade bond market now resembles one of those housing bubbles we’ve grown familiar with thanks to this website (Vancouver, the Bay Area, Manhattan etc): those who entered early made a killing. Those who entered a while later made a nice bundle. Those who entered late or are entering now will be lucky to make a profit reflecting the risks they are taking… prices are so insanely high even a 10% correction, not exactly the End of the World or even a bear market, can wipe out a significant part of a person’s life savings.
One set of data I’d like to see is who is buying those US equities and especially securities. The carry trade from Europe and Japan is surely very strong, but what truly intrigues and worries me at the same time is China. Since 2005, the People’s Bank of China (PBOC) has been an extremely strong buyer of US securities, concentrating especially on T-bills and muni bonds: this was chiefly done to help prop up the US dollar against the yuan and hence favor exports.
But in the past year and a half China seems to have reversed course, selling off US bonds (especially T-bills), especially through European outlets, apparently in a bid to fight capital flight, as the stated PBOC monetary goal always remains the same (weaken the yuan).
Is the PBOC back in the business of buying US bonds, giving the currency war precedence over capital flight? Or is this drop in yields merely the result of endless hedge funds, investors and savers piling on the same asset class?
Everyone thought I was nuts when I bought the US$-denominated Mexican 44’s in March 2015. Ok, my timing was not perfect. I could have gotten them 5% cheaper if I had waited two months.
Now 17 months have come and gone. I am bagging 4.75% annual interest and have a 5% appreciation in the bonds. Bought them through Vanguard’s bond desk – the bonds are readily salable.
CUSIP: 91086QBB3
United Mexican Sts MTN Be Glbl Nt 4.75%44, Make Whole Call
I understand governments want their economies stimulated and making government bonds not profitable is intended to make the investors put their money elsewhere, in hope of getting the economy moving.
The banks are not co-operating. It seems they see few good prospects for loans, apart from housing speculation and similar, and so are content to keep their money [as savings accounts] at the Fed, where the accounts are guaranteed. BTW the government never spends bond money, so it’s always there ready to pay back.
And few want to borrow…people instinctively avoid risk when central bankers pursue one experimental policy after another, the opposite of what these egg-heads think will happen. The paradox of thrift.
I don’t see where we go from here. If only a single central bank was buying bonds to drive down yields, you can see how this might ultimately destroy the currency and the market would correct (not happening in Japan, the most extreme case, or at least not yet). But if all major central banks are effectively colluding to buy trillions of dollars of bonds (with the effective promise of an unlimited additional amount) how do you get a correction? All types of assets are effectively priced to produce near zero nominal yield. I can see a compression of interest rate differentials; for equities (as profit growth reduces expected returns), or for corporate bonds (as defaults spike), but that is like to boost relative yields on the safest assets (e.g. Government bonds) even further.
I think you are on to something. Most of the ideas coming from the central banks will only work if one central bank does it. If they all do it, they cancel each other out.
Jim, you and an undisclosed central banker agree.
In an interview with Real Vision TV, Kyle Bass recounted a private, closed-door meeting with “one of the world’s top central bankers,” who told him: “You know Kyle, quantitative easing only works when you’re the only country doing it.”
Seems that the cbs are trapped in their egghead prison. Can’t think of any way out other than doing more of the same.
Interesting situation of panic buying of any asset class offering a positive yield. Meanwhile, The Federal Reserve reported Friday that total borrowing increased by $18.6 billion in May, up from a gain of $13.4 billion in April. It was the largest since a surge of $29.4 billion in March, which had been the biggest monthly increase on record. Borrowing in the auto and student loan category climbed $16.2 billion. Borrowing in the category that covers credit cards rose $2.4 billion. Cheap money will propel the country into oblivion thanks to the central bankers.
The investing “bragging rights” stories remind me of returning from Las Vegas and when talking to other passengers, you find that virtually ALL of them either “broke even” or made a “bundle”! I call BS.
Reminds me of the old line…went to Vegas is a $10k Cadillac and came back in a $50k bus.
As US treasuries look more appealing and the DXY grows, the US economy is going to nose dive hard.
Then we’ll start to see the real fireworks.
Just converted my last matured RRSPs into a RIF paying out at 1.3% as it is held and doled out monthly. It should take 6 years to squeeze the money out of the account and funnel into a tax-free savings account.
It is a pittance, really, but still in positive territory. I had a good laugh with the Financial Advisor about it. What a different world now than when I started my financial planning for retirement.
No bond purchases and no gold, either. I am waiting for another piece of land to come up which has a house on it that I will probably use as a rental. We also have vacant land in woodlot, pasture, and gardens/orchards, but as it only requires about $2,000/year in taxes to hold we think of it as a security blanket able to provide our food and heat if needed down the road. Vacant land has got to be the dumbest investment in the world, but at what price is peace of mind?
My wife and I made concious decisions years ago to define our assets and security in our terms, and as I see the wobbling and fear arise from current events mentioned above, I know that were right, (for us).
In order of importance, (assets):
*Relationships…Ours, other family members, and community.
* Health (regular exercise/activites and good diet)
* Attitudes (work ethic and sense of fun, gratitude)
* Skills (carpenter, welder, gardeners, fishing,cooking, plus others)
* Tools and knowledge how to use them
* Stores…(lumber, plumbing, fasteners, firearms and ammunition)
* Sound and comfortable home
* Free wood heat and good water source on property
* No debt and money at hand
I am sure that most people on this forum have far more in assets than we do and are very savvy investors. Furthermore, security in California or NY is going to look very different than security where I live. However, there is a time to make decisons and go forward with what you know and I think it needs to be well underway by the time one is 45 years old. It was only after children left home I could even think about options. When the kids were little I was broke with no extra money to invest. It was a real rat race, fun and rewarding, but very hard.
One more thing, you don’t realize how important health is until it is compromised. We take our days for granted until pain slaps us in the face. Sometimes, being pain free, having a full ‘fridge, and bottle of wine on the table is as good as life can be.
You can always toast your investment follies before digging in :-)
Inequality has gone too far.
In a world drowning in investment capital, negative interest rates have to be used to try and keep the stuff away.
Demand is so subdued there is nothing productive worth investing in and so people are willing to pay to have somewhere to park their money.
Get the impression things have gone too far?
Neoclassical economics assumes raw capitalism will reach stable equilibriums that benefit the majority.
The Euro-zone works on this assumption and we see the rich nations get richer and the poor nations get poorer. We then use austerity on the poorer nations to exacerbate the problem.
Has raw capitalism ever helped the majority?
We had small state, raw capitalism in the UK in the 19th Century, the wealthy lived in the lap of luxury and the poor lived in abject squalor. The vast majority were poor.
To maximise profits the wealthy used slave and child labour and only gave them up when regulations were put in place and they were compensated for the loss of their slaves.
Only through organised labour movements did the workers get a larger slice of the pie and it had nothing to do with raw capitalism itself.
Neoclassical economics was in use in the 1920s and its raw capitalism again led to massive inequality.
The wealthy had so much money to invest they got drawn into wild speculative bubbles. The Wall Street Crash and the Great depression came next.
Today everything is polarising again with massive inequality, with such subdued demand everyone is struggling.
How much longer can we believe in this neoclassical nonsense?
Neoclassical economics is preoccupied with the analysis of a fictitious world: Perfect competition , perfect consumer, perfect firms, perfect markets.
Not to mention the ABSENCE of a viable, sustainable commons!
Neoclassical economics was a tool to hide the discoveries of Classical Economics.
Normal problem solving:
1) Fully understand problem
2) Work out solution
Difficulty doing this with economics.
Obviously economists started off in the normal manner but pretty soon they started coming up with some unpleasant conclusions:
Adam Smith:
“The Labour and time of the poor is in civilised countries sacrificed to the maintaining of the rich in ease and luxury. The Landlord is maintained in idleness and luxury by the labour of his tenants. The moneyed man is supported by his extractions from the industrious merchant and the needy who are obliged to support him in ease by a return for the use of his money. But every savage has the full fruits of his own labours; there are no landlords, no usurers and no tax gatherers.”
Adam Smith saw landlords, usurers (bankers) and Government taxes as equally parasitic, all raising the cost of doing business.
He sees the lazy people at the top living off “unearned” income from their land and capital.
He sees the trickle up of Capitalism:
1) Those with excess capital collect rent and interest.
2) Those with insufficient capital pay rent and interest.
He differentiates between “earned” and “unearned” income.
Adam Smith:
“But the rate of profit does not, like rent and wages, rise with the prosperity and fall with the declension of the society. On the contrary, it is naturally low in rich and high in poor countries, and it is always highest in the countries which are going fastest to ruin.”
Exactly the opposite of today’s thinking, what does he mean?
When rates of profit are high, capitalism is cannibalising itself by:
1) Not engaging in long term investment for the future
2) Paying insufficient wages to maintain demand for its products and services
With conclusions like this Classical Economics became very unpopular with the wealthy.
What could they do?
They promoted another economics, neoclassical economics, whose conclusions were much more favourable to them.
Unfortunately, it doesn’t work because it is not based on the real world like Classical Economics.
Neoclassical economics:
You can ensure every mainstream economist is a neoclassical economist.
You can ensure neoclassical economics is rolled out across the world.
You can ensure neoclassical economics is the only economics taught at Universities.
You can sell its ideas to the masses with PR.
You can’t make it work.
RE: … Demand is so subdued there is nothing productive worth investing in and so people are willing to pay to have somewhere to park their money.
—–
IMNSHO this is where SS/OEs [state sponsored/owned enterprises] come in. When the private sector cannot or will not provide a needed good or service, the government must do so.
One suggestion, given the climate change/drought and projected food shortages, is the rapid development and deployment of LF/MSTRs [liquid fluoride/molten salt thorium reactors]. One major goal is to power massive numbers of desalinization plants and pumping stations/pipelines to provide water for crop irrigation. Another goal is the retrofitting of existing electricity generating plants and the gradual elimination of fossil fuel steam generation, with significant cost savings. There are many other benefits. http://mcduffee-associates.us/DROPBOX/LFTR01.pdf
That sounds far too advanced for the private sector.
I like the tech. sector in UK newspapers and the latest toys the private sector has developed.
China is building over 20 nuclear reactors right now, horribly over budget, and over schedule. Big government isn’t a panacea, especially in countries with endemic corruption.
RE: China is building over 20 nuclear reactors right now, horribly over budget, and over schedule. Big government isn’t a panacea, especially in countries with endemic corruption.
—–
>>>There are no panaceas.<<< That being said, in many cases it depends on what type of accounting you are using. It is entirely possible for an enterprise to show a “loss,” or at least no profit for a given activity, but under aggregate/holistic accounting the same activity may generate considerable net “profit” (or at least significant cost avoidance), and/or other socioeconomic/national benefits, i. e. as “loss leaders” for export.
You may well be correct that large developmental projects such as LF/MSTRs are beyond the capacity of any single private corporation to fund, which is why the creation of a SSE [state sponsored enterprise] in the form of a plain vanilla joint stock company is suggested, with the government owning/voting 51% of the stock, with the bylaws imposing limits on officer/director tenure/compensation, prohibiting relocation, limitation of the number of shares that a single owner can vote, etc.
Private sector partners could acquire stock by “payment in kind” by supplying engineering/design expertise, components, etc. Such organization would allow easy privatization if desired.
It would also be helpful if the SSE could also be “crowdsourced,” https://en.wikipedia.org/wiki/Crowdsourcing to involve as many people as possible, and “open sourced” to both allow the maximum amount of participation in the design of the physical unit and its control systems, and to disseminate the designs as widely as possible, analogous to Gethub https://github.com/ and the 3d printer “maker movement.” http://makerfaire.com/maker-movement/
Sots–The financial sector takes more and more to maximise it’s demands on profit. The left overs are growing less and less and this is where the 99% of us make our living. Do you think they care about our welfare given the scam leading up to 07 and 08? Neo feudalism is a fancy name for slavery but it’s the destiny of all but the one percent.
The current system is so biased it will collapse all be itself.
It’s a demand killer and even the IMF are starting to talk of redistribution through taxation.
“The Marxian capitalist has infinite shrewdness and cunning on everything except matters pertaining to his own ultimate survival. On these, he is not subject to education. He continues wilfully and reliably down the path to his own destruction”
Those at the top are always blind to who the consumers are that buy their products and services.
@Sound of the Suburbs,
Not to quibble, but you referred to “a world drowning in investment capital.”
I see it just a bit differently.
I would say that we are in a world drowning in counterfeit electronic money printed up by central banks.
While the trillion$ in central bank money-printing may have staved off economic collapse, it has brought about a host of other problems, chief of which is too much ‘money’ chasing too few investment opportunities.
Yes, Central banks have been printing money to keep asset bubbles inflated/inflating.
Private banks also create money and used it to blow up asset bubbles first, before the Central banks stepped in to carry on their work.
Some investigation into 1929 would have shown the collapse of the stock market and the effects that flowed out from there were due to lending on margin into the stock market, a debt inflated asset bubble.
Some investigation into 2008 would show the collapse of the US housing market and the effects that flowed out from there were due to excess lending into the US housing market, a debt inflated housing bubble. This time, complex financial instruments were used to leverage up the losses and transmit them around the world to make it even worse.
Actually Irving Fisher did look at the debt inflated asset bubble after the 1929 crash when ideas that markets reached stable equilibriums were beyond a joke.
Fisher developed a theory of economic crises called debt-deflation, which attributed the crises to the bursting of a credit bubble.
Hyman Minsky came up with “financial instability hypothesis” in 1974 and Steve Keen carries on with this work today.
Of course it as totally at odds with stable equilibriums and has to be ignored by neoclassical economics.
“Minsky Moments”
1929 – US (margin lending into US stocks)
1989 – Japan, UK (real estate)
1999 – US (margin lending into US stocks, not so much debt in this one)
2008 – US (real estate bubble leveraged up with derivatives for global contagion)
2010 – Ireland (real estate)
2012 – Spain (real estate)
Coming soon – Australia, Canada, Holland, Hong Kong, Sweden (real estate)
China is saturated in debt too, perhaps that will implode and many commentators seem to think so.
Hi Wolf,
I know this question is not related to this article, sorry, I gotta ask it.
I was trying to help a friend secure a place to rent and was shocked at the price of a monthly rental, 2700$ for a three bedroom house in an area with section 8 Apartments, high crime and crappy schools.
I know it’s because of “San Francisco” effect, but my question is this how does Section 8 vouchers play into this as well?
I’m pretty sure section 8 vouchers play into the bubble because they keep up with Market rental conditions.
Do any of the other posters have any Ideas?
Thanks, Gustave
Ps: if it helps the property is near the Intersections of MacArthur and Ritchie in deep East Oakland California.
I’m not familiar with Oakland’s apartment situation. That said, I know that a lot of people from SF are moving to Oakland (I know some myself) – and companies are setting up offices there, such as Uber – because it’s cheaper. But by doing this, they have fired up the Oakland RE market, and prices/rents are soaring!!!
While SF’s rents and prices appear to have hit a wall, this is not yet the case in Oakland.
I don’t know what influence Section 8 vouchers have on this, but in SF, they’re not a big factor (if any) on the level of rents. There are much bigger forces at play (money from all over the world).
Section 8 vouchers are a rent subsidy given to the renter, based on income, but ultimately it is a subsidy to the landlord. Landlords don’t generally like them because the low income renters lower the quality of their properties and neighborhoods. Once an apartment has been captured by section 8 it is essentially rent controlled. The landlord must continue to rent it, one a first come basis, to section 8 voucher holders, and the rent increases are also capped. However, landlords are business people and they will take the money when necessary, especially large corporate landlords with little interest in the community.
Agree that this is a rent subsidy that distorts the market. It’s the same in my country although we have different ‘section 8’ regulations.
In my country you qualify for this type of subsidized housing by having below median income and/or some kind of ‘disadvantaged’ status (single moms, divorced women, migrants etc.). In addition there are LONG waiting lists to get into social housing, in some cities up to 10 years, but again there are exceptions for ‘disadvantaged’ citizens.
Monthly cost for the renters is very low relative to the ‘free’ rental market, and capped in such a way that the cost difference between a simple apartment and a nice town house with garden is less than 10%. So people who rent in the social sector try to get into the best homes and stay there forever for an artificially low cost. Almost the complete stock of these subsidized homes is owned by housing corporations, former government (political) entities that were privatized over the years and now treat their managers like they are the brightest of the bankers. They make a lot of money, not from the relatively low rents but from the huge subsidies that the government pays them. Commercial / private landlords have almost disappeared from this market because they can’t make a profit – instead they cater to the very small ‘free’ rental market where rents are 2-4x higher than in the subsidized market – this works because the housing stock is kept artificially small and waiting lists for social housing are long.
Without government subsidies most of the homes in the subsidized sector would have FAR lower rents, because there is only so much people can afford. If you charge more the homes would be empty and not provide income at all (of course, who needs return on investment these days … it’s all about speculating, betting on selling off the investment to another idiot for an even higher price).
And without those huge subsidies for both social housing AND for private mortgages, home prices in the Netherlands would be several times lower than they are now – again because on their own almost no one can afford the current prices. It’s a Ponzi that is completely controlled by politics and benefits the banks, the RE mob and a big majority of the voters (and heavily punishes those rent in the free market, or those who own there home with little or no mortgage e.g. because they have significant capital but very low income). Some day the Dutch housing market is going to fail spectacularly, just like the tulip bubble from 400 years ago and some other manias that came after it. And it is only one of the many crazy distortions in our e-con-omy :-(
Waiting for an inverted yield to predict recession would disappoint based on current Fed Funds rate.
However, Fed has forced Fed Funds rate to zero, results scared Yellen when they ventured to boost rates just 1/4 point.
‘Normalized’ Fed Funds rate:
Normally, going back to the 70’s, Fed controls fund rate to be around 2% above what their best guess of what inflation actually is to control inflation.
Imagine that Yellen were to retire and Fed is taken over by inflation hawks, goaded by banks to boost rates so they can boost profits and, of course, bonuses.
So, they raise Fed funds to 3.5%, 2% above what current inflation seems to be, with justification that they were only doing what historically current inflation rate called for… what would happen?
Equities, supported only by low short term rates, would crash on account of excessive P/E and falling earnings. Ah, but the bonds…
Convinced the Fed was engineering a deep recession, maybe world wide, bond yields would crash as everybody buys, 10-year certainly under 1 and 30-year way under 2…
The point is that the implied Fed funds rate is 3.5%, and the longest bond is already substantially under that… all yields are on that basis seriously inverted.
The bond market seems to think this, otherwise how to explain why the 30-year bond is even lower now than just before Draghi promised ‘whatever it takes’ (2.47%, previous low), four years ago in July 24, 2012, when there was talk of states failing/eurozone breaking up?
And also note that Friday, with equities jumping to near record, the long bond fell to a new record. At some point these wildly diverging markets will once again agree.
I’m certain the paycheck to paycheck voting peasant man is just fascinated that large institutions have run out of places to place their mountains of money.
Negative bond rates are just another way the civil servants are getting their pound of flesh out of the banks.
Banks bounced terrified politicians into bailing them out and crowed about how smart and dynamic and enterprising they were afterward.
Bad move to make a civil servant look bad, because the civil service now want to see every penny back with interest.
Remember, civil servants are not allowed to be flamboyant and can’t make a killing on asparagus yields or buy yachts and give champagne parties when their oil short comes in.
What they have is their integrity and a sense of responsibility toward the public. Their image, if you will is very important to them – if an investment banker cares only about money, a civil servant only cares about prestige.
Therefore they do long-term, passive aggressive grinding very well, something flashy investment bankers just don’t have the endurance for. They have the financial institutions in a vice and are keeping them just about alive while they slowly suck the life out of them.
When they have their money back, however long that takes, they will discard the husks leaving the field to a new generation of meeker, chastened financiers who know their place, and hubris will have ended the way hubris always does.
I have to ask Wolf, what is the exact connection between this bond debacle and the potential for all of these companies and governments to go bankrupt simultaneously? I see that losing 12 trillion in the bond market would cause a massive domino effect though theoretically I thought that money was left somewhat payable and in fact bonds are usually one of the first in line for that payoff.
I can see your logic about this though in all fairness I don’t understand the dynamics at play here so let’s play hypothetical. If the market wakes up to this instability either when Britain hits negative in less than a year or when the US hits negative in a year and a half, what happens? You said many organizations unable to print money would go bankrupt simultaneously though what is causing that exactly? I know this isn’t exactly a causal relationship though please humor me in theorizing because if this happens as you say it will happen (very soon by the look of these rates of change), I’d like to be on the right side of it. That starts for me knowing exactly what causes it and knowing where the dominos are falling so I don’t get crushed.
Also on a side note I’m looking to cash in on these great mortgage rates buying a property and building an off grid house in Atlanta. If I do that would I be in substantial risk during a bubble or would that be a good move? I suppose from a logical standpoint I would rather have sustainable land if the government collapses though I don’t know what sort of pitfalls that would have.
Well, countries that issue debt in their own currency (like the US and Japan) CANNOT go bankrupt. They can always print more currency to pay their debts.
Countries that issue debt in a currency that they do not control (for example, Mexico issuing $ and € bonds) can go bankrupt. Hence the frequent debt crises in the emerging markets.
The Eurozone is a hybrid. France doesn’t control the euro, but it has a say in it, and the ECB will not allow it to go bankrupt, as you see right now: it’s printing money hand over fist and buying these bonds.
Companies, state and local governments, and consumers can go bankrupt. In that case, creditors will lose money. Stockholders get wiped out, while creditors get the assets or the company. The process works fairly well. If a lot of entities go through that process simultaneously, it gets a little rough.
If you have enough liquidity during that period, you can pick up some great bargains!