And it’s now hitting home.
The operative words have been “gradually” and “over time.” Just about all Fed governors use those or similar terms when they talk about removing “accommodation,” or tightening monetary policy, thereby gradually allowing the proverbial punch bowl to empty out, by refilling it each time a little less. That started in January 2015.
It is now happening on three levels: the dollar, interest rates, and even the Fed’s balance sheet – the one that everyone stopped looking at after QE Infinity ended.
As QE was breathing its last gasp, the Fed’s balance sheet reached $4,516.1 billion on January 14, 2015. Since then, the Fed has continued to buy Treasury securities and mortgage-backed securities to replace those that matured. So total assets, after a cursory look that made everyone happy, sort of remained the same:
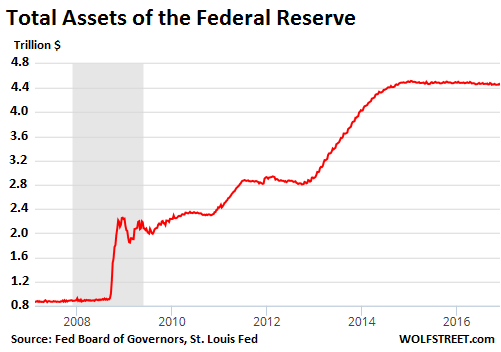
But increment by increment, practically hidden in the zigzagging line, the Fed’s balance sheet began to shrink. Total assets on the balance sheet now amount to $4,446.3 billion. That’s down $70 billion from the peak. Note the acceleration of the shrinkage since early 2016:
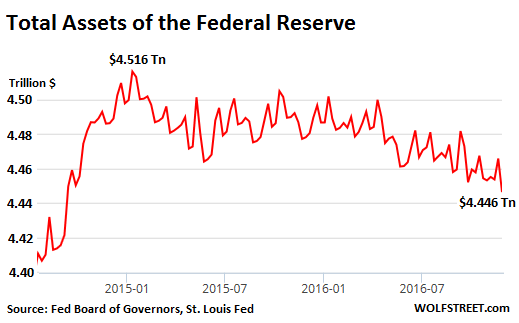
For now, “gradually” and “over time,” and without any kind of announcement to that effect, the Fed’s balance sheet has shrunk 1.55% in nearly two years.
The Fed’s largest position is US Treasury securities, at $2.46 trillion. That’s about flat from its position in January 2015. But within the group, there were some shifts, with some items falling, particularly “notes and bonds,” and with its position in “notes and bonds, inflation indexed” jumping 8% to $106.7 billion. Worried about something they told us was too small, such as inflation?
Mortgage backed securities, the second largest position, fell by $10 billion to $1.741 trillion. And “federal agency debt securities” plunged by $20 billion to $18.5. Clearly, the Fed is withdrawing support for the mortgage market, in micro-steps.
That $70 billion decline in total assets, spread over two years, reflects less than one month of QE Infinity. This is so slow and so uneven that it disappears in the noise of the data on a week-to-week basis. But it is happening.
Then there’s more tightening: the dollar. The dollar index, which measures the dollar’s movements against a basket of other major currencies, has jumped about 25%, from about 80 during the first half of 2014 to 100 in March 2015. It has since vacillated in the range between 93 and just over 100 and currently sits at 100.3.
And the official and highly publicized tightening: The Fed raised rates one tiny increment a year ago. Everyone is certain it will raise rates again next week. More rate increases are expected next year. Fed governors, even doves, have become more vigilant since Election Day, and have said so. And yields have jumped. The 10-year Treasury yield exceeded 2.4% for the first time since the summer of 2015 and now sits at 2.39% (vie StockCharts.com):
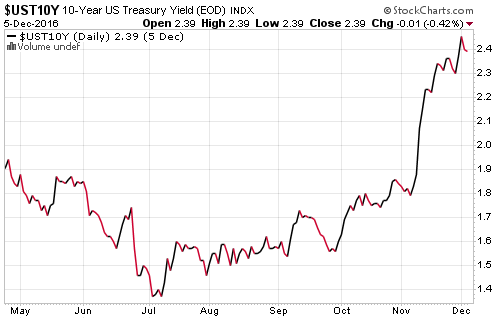
These higher Treasury yields have pushed up mortgage rates, with the 30-year fixed rate now at 4.17%.
And the Fed is OK with it all, with the shrinking balance sheet, the strong dollar, the rising yields, and the sharply higher mortgage rates. New York Fed President William Dudley, a dove, said so yesterday. Markets were beginning to think in terms of tightening, and were responding to it, and that was “broadly appropriate,” he said.
And there’s more to come: “I would favor making monetary policy somewhat less accommodative over time by gradually pushing up the level of short-term interest rates,” he said. The punch bowl will be refilled less and less, that’s the message, even though the economy is growing at the same “new normal” miserably slow rate as in prior years.
And the bond market is already doing the math. Read… Get Used to Lousy Growth AND Rising Rates: Fed Dove Dudley
Enjoy reading WOLF STREET and want to support it? You can donate. I appreciate it immensely. Click on the mug to find out how:

![]()
Sneaky is as sneaky does. Thanks for the analysis, Wolf. This is the sort of perspective Wall Street analysts will tend to ignore for one simple reason: t they get zero commissions on stocks they don’t sell.
Buyers remorse!
The low hanging fruit has disappeared?
I am clean man, I just need one more score?
Qe4 or the fed is dead?
What you think the new sheriff will do?
At the peak of the new normal the fed is going to drain the punchbowl and slow the raging 1.5 % growth wildfire?
Drain the swamp instead.
regarding mortgages:
” with the 30-year fixed rate now at 4.17%.”
I am 61. I easily remember rates around 20%. My knee jerk reaction to this statemnt is, “Call me when they hit 7%, then I’ll take notice”. Maybe then I’ll be making some money on my savings. These low rates for dodgy borrowers has been a travesty of reality, consequences, and expectations as far as I am concerned. The economy be dammned if that is what passes for economic health these days; (cheap debt).
My wife and I just returned from a walk this frosty clear and cold morning. The mountains are covered in snow and the creeks are steaming. There are trumpeter swans on the river and my coffee is a welcome warm-up. Cost? Nada. Nothing. Reward? Priceless. I guess we could climb into a financed $60,000 pickup and drive up to the ski hill and pay for $100 lift tickets (per) and $5.00 coffee on a credit card at 20%. Nah, we’ll do our own thing with our feet on the ground and no sleepless nights worrying about keeping the debt wheel turning. I guess we’re just old fashion poor folks living within their means.
I can’t wait for the first good snow near me. XC ski right out the back door. Great workout and amazing natural beauty. Price: almost zero
Over here in Europe the price might get high pretty soon: sky fields in the Alps are disappearing very quickly due to global warming; before you know it the few ski areas with good snow (or artificial snow …) will be reserved for the 0.1% ;-(
In my part of the Netherlands we haven’t seen real snow for 3 years and over the last 10 years or so there have been very few real winters that e.g. allow skating (ski is not an option here). When I was young there were often days with 10-40cm snowfall and the ice on the city canals was so thick that sometimes even trucks could drive on it. Nowadays 5 cm snow would already be newsworthy, and most years the ice on the canals is too thin that even for small children skating is dangerous.
You actually believe in “global warming” yet read Wolf’s commentary. How paradoxical….
@NM Rancher:
I’m a scientist (biochemistry and environmental chemistry) and I believe facts, not politically convenient BS. The general idea – mostly confined to the US – that global warming is a conspiracy
for me is very similar to creationism and other fallacies.
Just to be sure: this doesn’t mean that I agree with carbon tax / CO2 trading and other proposals that supposedly combat climate change (those could indeed be seen as a conspiracy …).
As a scientist you must be well aware of the cycles the earth has gone through. When I was at university in the 1970’s global cooling was the “fear of the day”.
You can run a straight regression line paralleling CO2 emission increases to the growth of China- the no pollution controls country. Yet Europe, like the United States, imports millions of tons of Chinese crap without any discussion whatsoever.
My poor XC skis are dying of neglect here in Illinois….no decent snow for ages
I remember when the 2008 crisis was called a “credit crisis”. Someone then made an apt remark that it’s not a credit crisis if you can still get a loan below 10%.
Walking in the hills won’t do anything to relieve the debt cycle pressure the way work does and everybody needs to pull together to pay off the old debts faster than we make new debts…….
I wish we got snow on our mountains….used to snow a lot in Colo. Sprgs.
I’m with ya Paulo, sittin here across the Strait … (waves from the Olympic Pennisula) …… looking out my windows at the wintery wonderland just outside … for free .. !!
No extra bs to clutter the day …. safer that way too !
There’s nothing to be ashamed about. Our society is now all inclusive!
I still do not understand (dense of something else?) how it is that the stock markets can keep going up while corporate earnings go down. Or how things are “improving” while more small business goes under than is created? Is there some magic elixir that is going to fix things in six months to a year?
1. Stock prices aren’t related to corporate earnings. They’re related to what the prices might be some time in the future. If everyone thinks they’re going up, they go up. No magic here.
2. Fewer small businesses mean more money for big businesses (yay WalMart). Also helps stock prices.
IMHO the relentless rise is mostly due to stock buybacks, NIRP/ZIRP rates for debt of big companies in recent times and “TINA”.
All the small businesses going under might also add to the bottom line of the big sharks, until there is nothing left to feed on…
They are not investing anymore. Money is on the run seeking safety. The smart money is very fearful of the bond market and government, so where do they have to park, in equities and property.
Just magical thinking.
I wonder how “ok” with the DXY at 105 the Fed will be? If the ten year keeps climbing while most first world sovereign debt stays NIRP, the USD is going to very likely leap up, causing all kinds of unwanted results. Extremely gradual change is what they want, but what if they don’t get it?
This article ignores that most other central banks are still in expansionary mode, especially the ECB; and a significant chunk of that money now ends up with US banks and multinationals. I don’t know how big the contribution is, but given that the FED ‘withdrawal of liquidity’ is next to nothing relative to the existing position, I bet that if you include QE etc. from other banks the trend in the US is still up.
IMHO the FED is all bark and no bite and determined to stay behind the curve forever. They have passed the baton to the other Goldman Sachs printing departments around the world and may be planning to step into the QE/NIRP game again soon, when the other banksters need a pause to refuel the printing presses.
As Paolo says, wake me up when mortgage and savings rates are back to normal (as in average for the last 100-400 years). I would not be surprised if that doesn’t happen in my lifetime, the current system simply cannot handle much higher rates.
Clearly they are not withdrawing support for the mortgage market because they are still holding on to the positions. If there was any real market for the mortgage or agency paper and the assets they hold had value, they could be unloaded. They are trying to ignite inflation and it can’t be done with a base of already worthless assets. Maybe they need to resolve this in bankruptcy court.
I see you have a new and bigger hammer to hit the nails with !
Always great and to the point comments.
The Fed and US Government have been painted tightly into a corner. The Fed knows damn well that higher interest rates will hurt the economy. But they jawbone in the other direction to save face and bide time (years, literally). Remember Bernanke stated that he wouldn’t see interest rates materially rise in his lifetime.
Now Mr. Trump wants to see interest rates rise back to a more normal level. If that happens (and it won’t be intentional), kiss the current ‘economy’ of the US goodbye….primarily housing, development and of course stock buybacks. Perhaps his plan is to unleash the avowed 1 trillion infrastructure stimulus to counter the implosion of the economy from interest rate increases and have everyone crossover from building and remodeling houses to laying asphalt and flagging cars on country roads.
Guess it could work. NOT.
To those who think it doesn’t matter until rates hit 10% or more, you are not understanding what’s going on.
It isn’t about rates compared to “normal” levels anymore. It’s about rates compared to the new normal.
Everyone is maxed out at these low rates, so even 5% will be more than enough to collapse this ponzi.
Think it won’t affect you cause you aren’t in debt? Your job, pension, savings, whatever you think will save you….won’t.
I don’t even care if you have a thousand ounces of gold in your possession. This is an orchestrated collapse whose intent is to take everyone with it, and it will.
You may be first or you may be last, but you will ultimately lose everything.
Prepare accordingly…
if you
Prepare accordingly…
why would you loose anything??
Living inland may cause you problems when they take the land.
Which they will
Do yourself a very big favor and read something Albert Einstein wrote in 1949. IMO, his recommendation is the only thing that can save the US economy / “society” of TODAY.
http://monthlyreview.org/2009/05/01/why-socialism/
If after reading it you think I’ve led you astray, please, please give me hell.
Assuming this article is not a fake, it is interesting how nothing has really changed in 67 years.
The article doesn’t address human motivation. Einstein was not an economist and his equating the study of economics to astronomy was erroneous.
Quote where he equated them.
“The achievement of socialism requires the solution of some extremely difficult socio-political problems: how is it possible, in view of the far-reaching centralization of political and economic power, to prevent bureaucracy from becoming all-powerful and overweening? How can the rights of the individual be protected and therewith a democratic counterweight to the power of bureaucracy be assured?”
No solution, Man’s fallen human nature will not allow it.
I’m not sure Capitalism has solved that problem either.
Why has the Fed’s balance sheet shrunk by 1.55% since QE ended? It is because some banks withdrew some reserves, or is it because the Fed took a 1.55% principal loss on some bonds that matured but did not get paid back in full?
The Fed’s “assets” on its “balance sheet” (the subject of this article) are securities, gold, and other assets it has acquired over time and that it owns. The “excess reserves” are not part of the Fed’s “assets” but are “liabilities.” They’re separate, and the Fed doesn’t own them, it owes them. And they looks like this:
(via https://fred.stlouisfed.org/series/EXCSRESNS)
The Fed has been very “profitable” and has been sending the majority of its profits to the Treasury every year. In 2015, a record $97.7 billion!
So there is no net principal loss, though it lost some money on some securities in its various Maiden Lane funds from the bailout era. But it made so much money on the $4.4 trillion in good assets that the relatively small losses just don’t weigh much in the overall accounting.
It’s really an awesome business model: create money out of nothing, buy securities with it, and call that yield “profit.”
Thanks Wolf. You really cleared things up for me. Could they go under from losses or is that just not possible?
Doesn’t seem right they can have such a free ride and much of the rest of us have to work and struggle for profits.
I don’t think that a central bank that can print its own money can “go under” from its losses. They can always “print” more money.
But the currency might go under, or at least take a huge hit :-]
Since no one that the Fed represents would profit from a collapse of the dollar, the Fed is unlikely to create that situation. They want gradual, controlled, and predictable inflation – not a collapse of the dollar. And I think that’s pretty much what we’ll get.
How did that get up there
Wolf
Good article .
I predicted this as their exit strategy, years ago ( QE2) when people first started asking how and when they would unwind/exit..
If America ever gets any heat back into its economy the shrinkage rate will increase.
Good pick
To post an image, I have to upload it to my server, create the html code that is needed to display the image on the site, and then copy and paste that html code into the comment.
Every hacker would want to upload things to my server, so this activity is highly restricted, and (hopefully) only I can do that :-]
I hesitate to ask again, since I seem to have gotten in trouble about this reserve thing before, but I assure you that my intentions are purely knowledge and logic, and not some kind of trolling.
So: My understanding is that ANY asset that the Fed owns, apart from fundamental capital and temporary profits, must correspond to reserves (mandatory reserves plus excess reserves) on the liability side of the Fed balance sheet.
When a bank withdraws excess reserves, the mechanism for withdrawal is to buy some of the Fed’s assets (typically securities) with it. The banks gets the securities as an asset to book, and the payment is deducted from the reserves. On the Fed balance sheet, assets and liabilities are both reduced.
So my understanding is that Fed asset values may be reduced either via losses OR via withdrawal of reserves. Hence my original question about whether the 1.55% asset balance drop was from losses of principal on some bad bond assets, or due to reserve withdrawals. Seems like a logical question to ask.
I’m sort of ducking for cover now, but I guess I’m still insisting that reserves (Fed liabilities) must be backed by SOME corresponding Fed assets. Whether these assets are gold, safe bonds, crappy bonds, or even (risky) stocks, as Bank of Japan has been doing in 2016.
Ish and Kent
I agree with Dr. Morris Berman, that our country was founded by European hustlers and thieves, and that has been our m.o. ever since.
This will soon be our downfall. It is probably too late to change. Read his books. They are very persuasive.
Once again, a small voice from the counterculture: no debts here. Savings (shudder! How unpatriotic.) instead.
Up ’til recently, I got 1.5 % on my checking account, up to $15,000 (anything above that amount gets the typical bank savings account interest, a fraction of 1%, so my surplus cash above 15,000 isn’t there).
Wolf’s observation of gradually rising interest rates is borne out, even in my “peon’s” experience: in my Federal Credit Union, the rate on checking account balances was recently raised to 2%.
As Wolf has implied elsewhere, the commercial banks might not pass along any of the benefits of higher interest rates to their savings account customers.
Aside: Back in my Patent Examining days, I commuted to Washington from Warrenton, Virginia with Doug Smith, the President of then National Savings and Trust, where Marjorie Merriwether Post was a patron. (how’s that for name dropping?)
Doug hated credit unions and said so – they paid no taxes, etc.etc.
We had some interesting discussions over the road and back home.
Wolf how about doing a comparison of the functions of what used to be called “savings banks”, and credit unions?
Back when I was in grad school, I wrote an accounting thesis on one of the biggest S&Ls – on what they were doing to show profits. This was in 1985, before the S&L scandal broke, and I had no public knowledge about this. I was just digging. My prof took the paper to a buddy of his at the FBI and then relayed back to me – after I had to swear that I wouldn’t tell anyone – that his buddy had told him that they had a room full of documents, and that they were trying to figure out what these S&Ls were doing….
So I don’t want to compare the S&Ls to credit unions, which I respect a lot. I used to be member of a credit union and used to be on its advisory council. This is really a different sort of banking. It doesn’t work for everyone. But they’re a good deal.
I find it a bit difficult to understand how they will survive the massively stronger dollar. It will kill exports.
Tariffs my friend, tariffs.
I wonder if the solution they are thinking of is another massive QE to relieve dollar strength with the intention to raise rates concurrently in order to mitigate some of the inflation. We can call this QE “tax cuts”. The effects of this tax cuts, however, will be dimished as most of the benefits will be felt at the top.
How much of this new debt will be bought domestically and how much of it will be bought overseas? These are the answers I will be waiting for.
Ray, have you ever heard the expression “circle jerk”? I think that it best expresses the “whatever it takes” relationship among the central banks of the US’s vassal states, the IMF and the BIS. Whenever a nation’s bank needs some more “liquidity” or a bond-buyer of last resort, the others in the circle lend a hand to the one experiencing the most pressure.
Excess reserves are Fed liabilities and are matched by assets on its balance sheet. There has been stealth tightening as half of QE3 has been reversed.
The QE3 reversal has been mostly offset by increases in currency in circulation and the U.S. Treasury checking account.
Year over year, currency up $80 billion and checking account up $385 billion.
https://www.federalreserve.gov/monetarypolicy/files/quarterly_balance_sheet_developments_report_201611.pdf
You know, and I know, that the ultimate end and GOAL of all this will be the shrinking of the Fed’s balance sheet via ‘retirement’ of Fed-held debt…the final solution.
And the stupid ‘markets’ and brain-dead consumers will never notice.
We’ve seen the after-effects of zero interest rates in Japan and what negative interest rates have done to Europe. In an aging worldwide population savers will go broke and become destitute resulting in the state having to fund “their” existence. Presently the U.S. stock market is the most overvalued ‘in history past, present and future (it was past and present). Hopefully rising interest rates will convince people to sell “their” stocks and avoid losing most of their net worth in a repeat of the ’29 crash. The way I see it rising interest rates can only be a good thing for the worldwide economies at least see interest rates above their respective inflation rates instead of below.